
مقدمه
برای درک اهمیت و مفهوم حافظه در FPGA ابتدا باید با انواع آن آشنا شویم. حافظهها یکی از مهمترین منابع درون تراشه FPGA هستند و بدون آنها جریان طراحی به شکلی که امروزه انجام میشود، امکان پذیر نبود. در حالت کلی حافظهها درون FPGA به دو دسته تقسیم میشوند:
- حافظههای بلوکی یا Block RAM
- حافظههای توزیع شده یا Distributed RAM
در این آموزش از پایگاه دانش هگزالینکس قصد داریم مروری بر انواع حافظهها در FPGA داشته باشیم. مفهوم حافظه در FPGA و کاربرد آن تا حدودی با ذهنیت اولیه ما از حافظه متفاوت است. برخلاف پردازندهها که از حافظه برای فراخوانی دستورالعملها و دادهها استفاده میکنند، در FPGA حافظهها به عنوان بخشی از مدارات دیجیتال به موازی سازی پردازشها و انعطاف پذیرتر کردن طرح کمک میکنند. پس تا انتها با ما همراه باشید.
حافظههای بلوکی
حافظههای بلوکی یکسری منابع اختصاصی سخت افزاری هستند و به صورت بلوکهایی با ظرفیت ذخیره سازی چند ۱۰ کیلوبیت روی تراشههای FPGA قابل فراخوانی هستند. ظرفیت هر کدام از بلوکهای حافظه در تراشههای سری ۷ برابر با ۳۶ کیلوبیت است. البته به صورت بلوکهای حافظه ۱۸ کیلوبیتی نیز قابل استفاده هستند. با توجه به سری ساخت FPGA و نوع آن بلوکهای حافظه ممکن است ظرفیت پایینتری داشته باشند. به عنوان مثال، برای تراشههای Spartan-6 ظرفیت ذخیره سازی یک بلوک حافظه ۱۸ کیلوبیت است و در صورت نیاز میتواند به صورت یک بلوک ۹ کیلوبیتی نیز استفاده شود.
این که چه تعداد از این بلوکهای حافظه در هر FPGA وجود دارد، بستگی به نوع آن دارد. به عنوان مثال کوچکترین تراشه سری ۷ یعنی تراشه XC7S6 از خانواده Spartan-7 تنها ۵ بلوک حافظه ۳۶ کیلوبیتی دارد در حالی که تراشههای قدرتمند خانواده Virtex-7 میتوانند تا ۱۸۸۰ بلوک حافظه داشته باشند. یعنی ظرفیت ذخیره سازی حدود ۶۸مگابیت !!! تعداد بلوکهای حافظه برای تراشههای خانواده Spartan-6 بین ۱۲ تا ۲۶۸ بلوک ۱۶ کیلوبیتی متغیر است.
کوچکترین تراشه FPGA سری ۷ یعنی تراشه XC7S6 از خانواده Spartan-7 تنها ۵ بلوک حافظه ۳۶ کیلوبیتی دارد.
زمانی که هر کدام از این بلوکهای حافظه توسط طراح فراخوانی شوند، فارغ از اینکه چه مقدار اطلاعات قرار است در آنها ذخیره شود، کل فضای ذخیره سازی آن بلوک مورد استفاده قرار میگیرد. به عنوان مثال فرض کنید قرار است ۱۲۸ کلمه ۱۶ بیتی را درون یک حافظه بلوکی روی یکی از تراشههای Spartan-6 پیاده سازی کنیم. یعنی ۲۰۴۸ بیت یا ۲ کیلوبیت داده، در صورت استفاده از یک حافظه ۹ کیلوبیتی درون تراشه واضح است که ۷ کیلوبیت آن بدون استفاده باقی میماند و این یک اشکال در طراحی است. اجازه بدهید بحث در رابطه با حافظههای بلوکی را در همینجا متوقف کنیم و کمی به حافظههای توزیع شده بپردازیم.
حافظههای توزیع شده
برخلاف حافظههای بلوکی حافظههای توزیع شده، منابع اختصاصی سخت افزاری نیستند، و با استفاده از LUT ها ساخته میشوند. همانطور که از نامشان میتوان تشخیص داد، میتوانند در هر جایی از تراشه پیاده سازی شوند. این حافظهها قابلیت ذخیره سازی تعداد محدودی بیت دارند و در مواردی که نیاز به ذخیره سازی حجم کمی از دادهها وجود داشته باشد، مورد استفاده قرار میگیرند. ظرفیت ذخیره سازی این حافظهها ثابت نیست و میتوانند کاملا سفارشی شده باشند. برای تراشه XC7S6 که پیشتر به عنوان کوچکترین تراشه خانواده Spartan-7 معرفی شد، کل ظرفیت حافظههای توزیع شده برابر با ۷۰ کیلوبیت است. این عدد برای بزرگترین تراشه خانواده Virtex-7 حدود ۲۱ مگابیت است.
حافظههای توزیع شده، منابع اختصاصی سخت افزاری نیستند، و با استفاده از LUT ها ساخته میشوند.
در حالت کلی LUT ها برای انجام روابط منطقی بکار گرفته میشوند اما LUT های درون اسلایسهای کامل (SLICEM)، میتوانند به صورت حافظه پیکرهبندی شوند. هر LUT در تراشههای سری ۷ قابلیت ذخیره سازی حداکثر ۶۴ بیت داده را دارد و با اتصال آبشاری LUT های درون یک اسلایس امکان افزایش این ظرفیت تا ۲۵۶ بیت نیز وجود دارد. البته با استفاده از چندین اسلایس و بخشی از منایع دیگر FPGA امکان افزایش ظرفیت حافظههای توزیع شده وجود دارد. به عنوان مثال با استفاده از ۱۶ اسلایس میتوان یک حافظه ۱۶ بیتی با عمق ذخیره سازی ۶۴ کلمه تولید کرد یعنی یک حافظه ۱ کیلوبیتی.
از کدام حافظه استفاده کنیم؟
حالا سوال اینجاست، برای طراحی از کدام حافظه استفاده کنیم؟ یا سوال مهمتر اینکه چگونه این حافظهها را در کدهای خودمان فراخوانی کنیم؟ چگونه پیکرهبندی آنها را تنظیم کنیم؟ پاسخ به این سوال بسیار ساده است، فقط باید درست کد نویسی انجام دهیم. ابزار سنتز به صورت اتوماتیک حافظهها را به منابع درون تراشه نگاشت میکند. یعنی ابزار سنتز با توجه به ظرفیت حافظه بهترین جایگاه را برای پیاده سازی انتخاب میکند.
با کدنویسی صحیح، ابزار سنتز به صورت اتوماتیک حافظهها را به منابع درون تراشه نگاشت میکند. البته برای فراخوانی انواع حافظهها از IPCore ها نیز میتوان استفاده کرد.
به صورت پیش فرض حافظههای توزیع شده دارای ورودی سنکرون و خروجی آسنکرون هستند. اما با استفاده از رجیسترهای موجود در خروجی هر اسلایس میتوان خروجیها را نیز به صورت سنکرون مورد استفاده قرار داد، این کار باعث بالا رفتن کارایی حافظهها در سرعتهای کلاک بالا میشود. اگر چه یک کلاک تاخیر نیز در خروجی ایجاد میکند. با توجه به نیازهای هر سیستم، مهندس طراح میتواند حافظههای توزیع شده در تراشههای سری ۷ را به چهار صورت پیکرهبندی کند، که به شرح زیر است.
- تک پورت: در این پیکرهبندی یک پورت برای خواندن آسنکرون و نوشتن سنکرون در نظر گرفته میشود.
- دو پورت: در این پیکرهبندی یک پورت برای خواندن یا نوشتن و یک پورت نیز برای خواندن آسنکرون در نظر گرفته میشود.
- دو پورت ساده: در این پیکرهبندی یک پورت برای نوشتن و یک پورت نیز برای خواندن آسنکرون در نظر گرفته میشود.
- چهار پورت: در این پیکرهبندی یک پورت برای خواندن یا نوشتن و سه پورت نیز برای خواندن آسنکرون در نظر گرفته میشود.
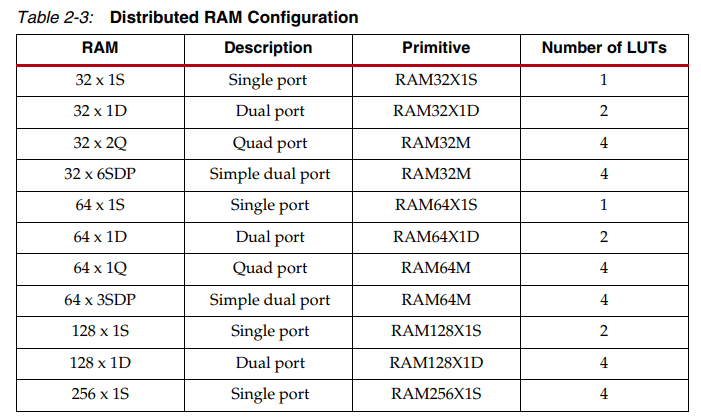
اطلاع از نحوه به اشتراک گذاری پورتهای کنترلی و محدودیتهای بکارگیری هر کدام از پیکرهبندیهای فوق جز مهارتهای تکمیلی یک مهندس پیاده ساز محسوب میگردد.
همه خانوادههای تراشههای سری ۷ از یک ساختار یکسان در بلوکهای حافظه استفاده میکنند. بلوکهای حافظه همگی عملکرد سنکرون دارند، یعنی یک رجیستر در پورت خروجی این بلوکها قرار داده شده است. هر بار که فرمان خواندن از این حافظه ها صادر شود، خروجی با یک کلاک تاخیر و البته به صورت سنکرون آماده میشود. این رجیستر پایپلاین نیز مشابه رجیستر اضافی در خروجی حافظههای توزیع شده عمل میکند و باعث افزایش کارایی حافظه در کاربردهای فرکانس بالا میشود. ساختار بلوکهای حافظه به صورت پیش فرض از دو پورت پشتیبانی میکند، که هر دو پورت به یک فضای یکسان از حافظه دسترسی دارند. هر پورت دارای کلاک، ورودی آدرس، ورودی فعال ساز کلاک و ورودی فرمان مستقل برای خواندن از حافظه است.
حافظههای بلوکی دارای رجیستر اختصاصی در پورت خروجی هستند.
حداکثر عرض بیت قابل پشتیبانی در حافظههای بلوکی ۷۲ بیت است. هر پورت میتواند برای پشتیبانی از عرض بیت مستقل پیکرهبندی شود. علاوه بر این امکان نوشتن در این حافظهها به صورت بایت به بایت نیز وجود دارد. به بیان سادهتر میتوان در یک آدرس از حافظه که توانایی ذخیره سازی مثلا ۱۶ بیت را دارد، دو بار در یک کلاک مقادیر ۸ بیتی نوشت. این قابلیت، یک مزیت بسیار کلیدی در هنگام استفاده از پردازنده کمکی همچون میکروبلیز (MicroBlaze) فراهم میآورد.
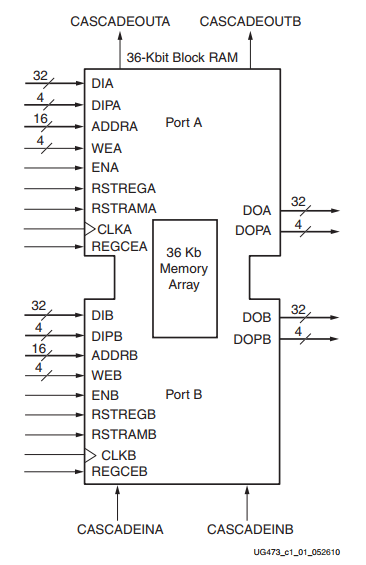
حافظه های بلوکی به صورتهای زیر قابل پیکرهبندی هستند:
- تک پورت: در این پیکرهبندی از یک پورت برای خواندن و نوشتن به صورت سنکرون استفاده میشود.
- دو پورت ساده: در این پیکرهبندی از یک پورت برای خواندن و از یک پورت برای نوشتن استفاده میشود، هر کدام از پورتها دارای کلاک و سیگنالهای کنترلی مستقل هستند.
- دو پورت کامل: در این پیکرهبندی دو پورت کاملا مستقل برای خواندن و نوشتن وجود دارد، کلاکها و سیگنالهای کنترلی پورتها مستقل از هم هستند و حداکثر انعطاف پذیری را برای کنترل فرایند خواندن و نوشتن در اختیار کاربر قرار میدهند.
نوشتن در حافظههای بلوکی میتواند با سه اولویت بندی متفاوت صورت بگیرد، این سه مد اولویتبندی عبارتند از:
- مد WRITE_FIRST : داده نوشته شده در پورت ورودی A روی پورت خروجی A قرار میگیرد.
- مد READ_FIRST : مقدار قبلی نوشته شده در حافظه در پورت آدرس A روی پورت خروجی A قرار میگیرد.
- مد NO_CHANGE : برای کاهش توان مصرفی در زمان نوشتن روی حافظه، پورت خروجی A همواره مقدار قبلیش را حفظ میکند .
جمع بندی
ممکن است در نگاه اول فراگیری مطالب فوق کمی سخت به نظر برسد، که البته اینطور نیست و با کمی تکرار کاملاً قابل درک است. ضمنأ بد نیست به این نکته توجه داشته باشیم که هم حافظههای توزیع شده و هم حافظههای بلوکی با استفاده از IPCore های شرکت Xilinx قابل فراخوانی و سفارشی سازی هستند. طراح به راحتی میتواند با انتخاب پیکرهبندی مورد نیازش به سریع ترین و بهینه ترین شکل ممکن حافظهها را به کار بگیرد. با استفاده از IPCore ها امکان فراخوانی پیکرهبندیهای اضافی با ترکیب کردن بلوکهای حافظه و منابع منطقی نیز وجود دارد، که بهترین مثال آن پیکرهبندی FIFO پرسرعت است.
در انتها ذکر یک نکته ضروری است، علاوه بر دو ساختارِ معرفی شده، بلوکهای حافظه جدیدی در خانواده +UltraScale شرکت Xilinx معرفی شدهاند که حافظههای اولترا یا UltraRAM نام دارند. برای آشنایی با این عناصر جدید حافظه میتوانید مقاله بلوکهای UltraRAM در تراشههای +UltraScale را در پایگاه دانش هگزالینکس مطالعه بفرمایید.






4 دیدگاه برای “مفهوم حافظه در FPGA و کاربردهای آن”
سلام . ممنون
فقط سوال اینکه چه زمانی از نوع بلوکی استفاده کنیم و چه زمانی توزیع شده؟
آیا تعیین این موضوع به نوع برد و مسئله و تعداد Block و LUT موجود مربوط می شود؟
سلام حمید عزیز
در حالت کلی شما می توانید انتخاب بین حافظهها را به خود ابزار بسپارید، هم ISE و هم Vivado بر اساس تنظیمات پیش فرض خودشان قادر هستند حافظه مناسب را برای طرح شما فراخوانی کنند. نوع بورد، و نوع تراشه مورد استفاده در انتخاب نوع حافظه تأثیر گذار نیست. تمامی تراشههای فعلی Xilinx از هر دو نوع استفاده میکنند و تنها تعدادشان متقاوت است، چیزی که اهمیت دارد نحوه کدنویسی و سایز حافظه مورد نیاز هست. معمولاً حافظههای کوچکتر به صورت توزیع شده سنتز میشوند.
پیروز و پاینده باشید.
عالی بود.