
مقدمه
در مقاله کار با حلقهها در HLS با چگونگی بهینه سازی حلقهها در کدهای HLS آشنا شدیم. روش یکپارچه کردن، ترکیب کردن و باز کردن حلقهها را روی کدهای عملی بررسی کردیم. در این مطلب قصد داریم، چگونگی بهینه سازی به کمک analysis perspective در محیط Vivado-HLS را با هم مرور کنیم. بنابراین در انتهای این مقاله قادر خواهیم بود با تحلیل نتایج پیادهسازی بهترین الگو برای اعمال تغییرات روی ساختار کدها را شناسایی کنیم و در مییابیم که چه شکل از بهینه سازی در افزایش کارایی کدهای HLS تاثیرگذارتر است. اگر علاقمند به این موضوع هستید تا انتها با ما همراه باشید.
تحلیل عملکرد و روند اجرای کدها
در آغاز کار به عنوان اولین مثال، اجازه بدهید به مثال ترکیب حلقهها در مقاله کار با حلقهها در HLS برگردیم، و نگاهی مجدد به آن بیاندازیم. با یک حلقه تکی تأخیر طرح ما حدود ۳۵۳ کلاک است. یعنی بعد از ۳۵۳ کلاک طرح ما قادر است کار پردازش یک ورودی جدید را آغاز کند. این گزارش در برگه خلاصه نتایج سنتز به سادگی در دسترس است. اما برای بالابردن کیفیت بهینه سازی طرح، بهتر است کمی وارد جزئیات بشویم و در رابطه با گلوگاه اصلی طرح که منجربه به بالا رفتن تأخیر شده است، اطلاعات بیشتری بدست بیاوریم.

این اطلاعات جزئی تر در نمایش analysis perspective در اختیار ما قرار میگیرد. کافی در سمت راست و بالای ابزار Vivado-HLS روی گزینه analysis perspective کلیک کنیم.
محتویات این نمایش بعد از سنتز کدهای HLS فعال میشود و اطلاعات تکمیلی در رابطه با ساختار و سلسله مراتب کد، منابع مصرفی و از همه مهتر تأخیر طرح را ارائه میدهد.
در داخل analysis perspective چندین پنجره و برگه وجود دارد که با آرایش خاص در کنار هم چیده شدهاند و برای بهینه سازی طرح به عنوانی ابزارهای کمکی در اختیار ما قرار دارند.
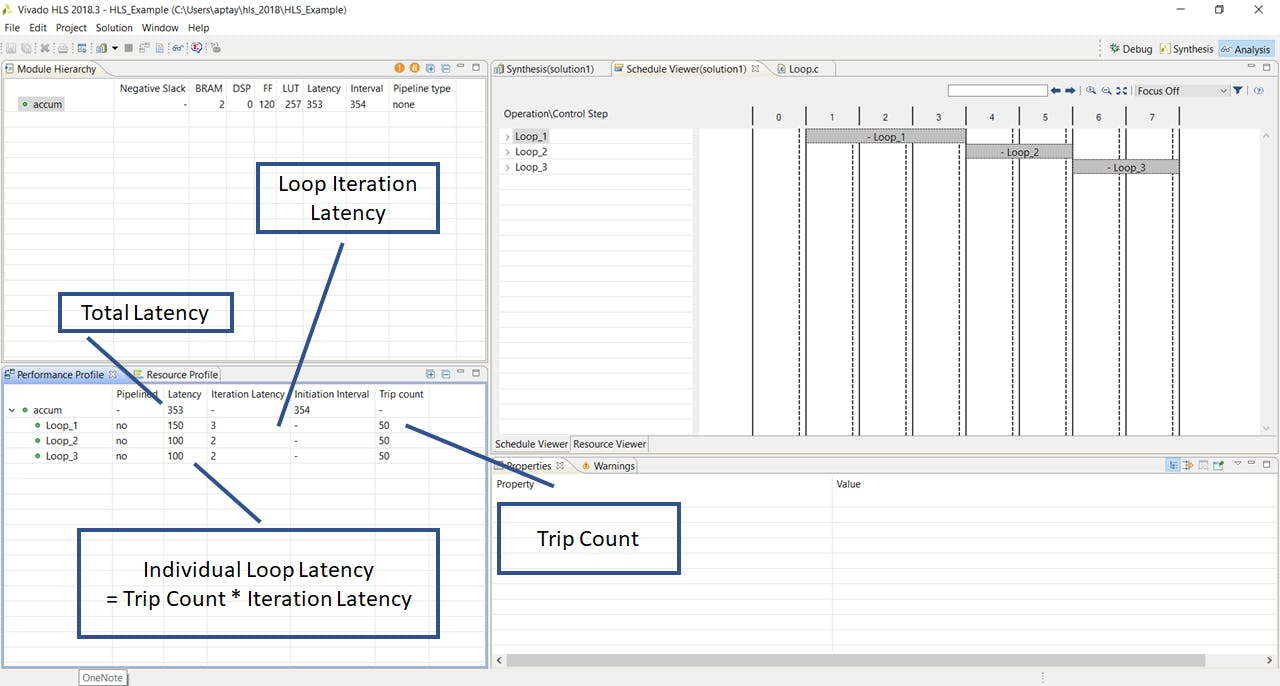
با در نظر گرفتن مثال ترکیب حلقههای در پروژه قبلی، در برگه performance profile در سمت چپ و پایین نمایش analysis perspective ما سه حلقه را در درون فانکشن accum ملاحظه میکنیم. برای هر کدام از حلقهها تأخیر مجموع (latency) به صورت جداگانه گزارش شده است. این تأخیر حاصلضرب پارامترهای tripcount و iteration latency است. حتما بیاد دارید که
- پارامتر tripcount تعداد دفعات اجرای حلقه و
- پارامتر iteration latency تعداد کلاکهای مورد نیاز برای اجرای کامل یک تکرار از حلقه است.
وقتی صحبت از بهینه سازی کارایی یک طرح با حلقههای متعدد به میان میآید، ما معمولا تمایل داریم ابتدا تأخیر ناشی از اجرای یک تکرار از حلقه (iteration latency) را کمینه کنیم. با این کار یکی از پارامترهای تاثیر گذار در تأخیر مجموع را کاهش میدهیم. در گام دوم، بعد از کاهش تأخیر ناشی از هر بار اجرای حلقه، میتوانیم تعداد دفعات اجرای حلقه را نیز کاهش دهیم (یعنی کاهش پارامتر tripcount).
پس کارمان را با کاهش تأخیر اجرای هر حلقه آغاز میکنیم. برای درک بهتر این که دقیقاً چه چیزی باعث افزایش تأخیر اجرای حلقه میشود، بهترین گزینه استفاده از برگه schedule viewer است.
برگه schedule viewer برای ما این امکان را فراهم میآورد تا در کنار مشاهده روند اجرای محاسبات، دسترسی به سورس کدهای تاثیرگذار در هر عملیات نیز داشته باشیم. در واقع این قابلیت به ما اجازه میدهد درک بهتری از نحوه اجرای هر خط از کد HLS بدست بیاوریم.
در مثال زیر، شما میتوانید حجم عملیات سربار ناشی از در خواستهای متعدد برای خواندن از یک بلوک حافظه را مشاهده کنید. این حافظه وظیفه نگه داشتن مقدار متغیر A را برعهده دارد. خواندنهای پیاپی باعث افزایش تأخیر حلقه میشود. این تأخیر اضافی برابر یا یک کلاک است و منجربه افزایش تأخیر کل میشود.

ما میتوانیم از این اطلاعات برای شکستن و ویرایش شیوره خواندن از BRAM در کدهای HLS استفاده کنیم. متغیر A در برگه schedule viewer درون بلوک حافظه BRAM دخیره شده است. برای شکستن حافظه و از بین بردن محدودیت دسترسی به این متغیر ما از پراگمای array_partition به صورت زیر استفاده میکنیم.
// pragma #pragma HLS ARRAY_PARTITION variable=a complete dim=1
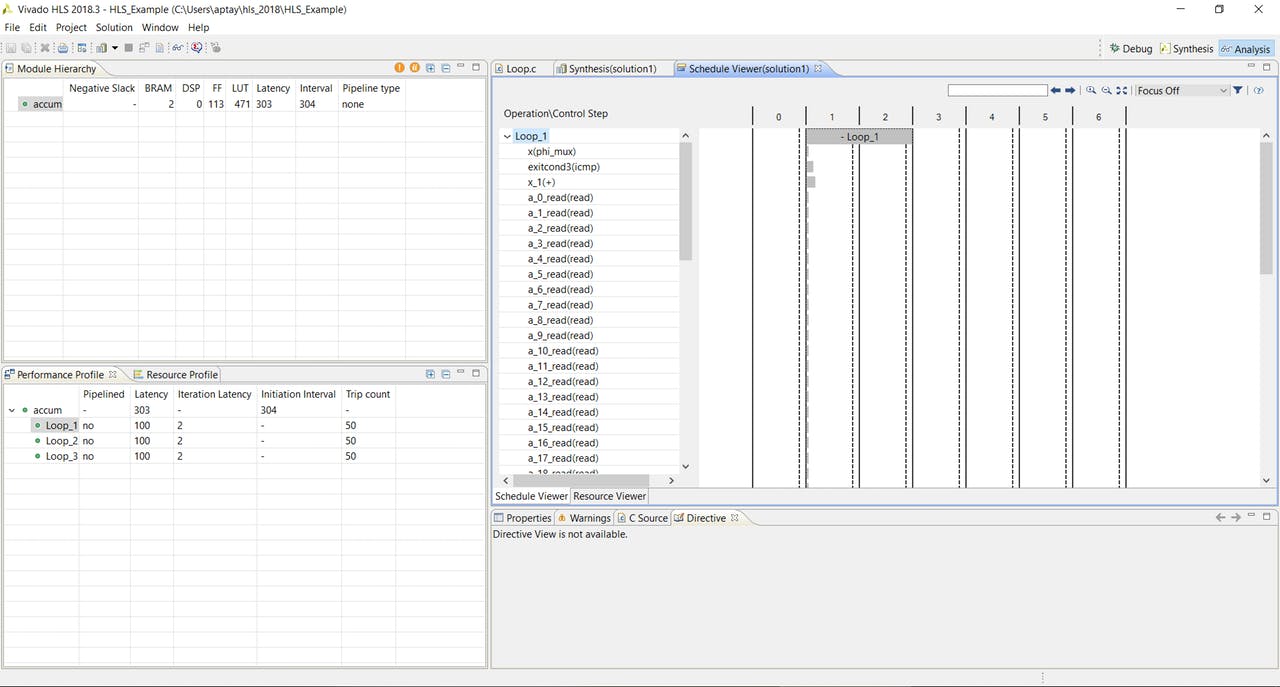
سنتز مجدد طرح نتایج جالبی را به همراه دارد. کاهش قابل توجهی در تأخیر مجموع شکل گرفته است. تأخیر حلقه اول (loop_1) به حدود یک سوم کاهش پیدا کرده است و برابر با ۱۰۰ کلاک شده است. علاوه بر این تعداد کلاک مورد نیاز برای هر اجرای حلقه از ۳ به ۲ کلاک کاهش پیدا کرده است. اما با وجود تمام این بهبودها بازهم تأخیر مجموع زیاد است و اجرای محاسبات به چیزی حدود ۳۰۳ کلاک زمان نیاز دارد.
با کمی دقت بیشتر در schedule viewer اگر روی علامت بعلاوه کنار حلقه اول کلیک کنیم مشاهده میکنیم که ۵۰ مقدار از A به صورت همزمان به عنوان ورودی مورد استفاده قرار میگیرند. این بدان معناست که محدودیتهای استفاده از پورتهای حافظه از بین رفته است و اکنون به جای یک دسترسی، پنجاه دسترسی موازی به متغیر A داریم. علاوه بر این کاهش زمان اجرای حلقه به ۲ کلاک نیز در این برگه قابل مشاهده است.
با اعمال پراگرمای پارتیشن بندی آرایهها (array_partition) به بلوکهای حافظه و سپس ترکیب حلقهها مشابه کاری که در مطلب کار با حلقهها انجام دادیم، ما قادر به دستیابی به کارایی بهتری نسبت به حالت قبل که تنها حلقهها را با هم ترکیب کردیم، میباشیم.
کاهش پارامتر iteration interval از ۱۰۲ کلاک به ۵۲ کلاک، کاملاً برای ما مطلوب است. توجه داشته باشید در مجموع زمان پذیرش دادههای جدید (iteration interval) از ۳۵۴ کلاک به ۵۲ کلاک کاهش پیدا کرده است که مقداری بسیار قابل توجه است.
البته، ذکر این نکته حائز اهمیت است که در این پروژه ما جریان بهینه سازی را با اولویت بهبود کارایی سیستم مدیریت کردیم. در اینجا روش انتخابی ما منجربه افزایش منابع مصرفی شد و این یعنی ما منابع مصرفی را فدای کارایی سیستم کردیم. اگر چه در این مثال کوچک ممکن است افزایش منابع مصرفی برای ما مشکل ساز نباشد، اما همیشه اینطور نیست و باید این نکته را نیز مدنظر قرار دهیم.
جمع بندی
امیدوارم با خواندن این مطلب کمی بیشتر از گذشته، با روش استفاده از analysis perspective برای بهینه سازی طراحیها در Vivado-HLS آشنا شده باشید. بدون شک بهینه سازی به کمک analysis perspective در کنار سادگی، به شدت ارزشمند است.
منبع: برگرفته از hackster.io نوشته Adam Taylor





