مقدمه
بعد از زبانهای HDL که جایگزین طراحی شماتیک در سطح گیت شدند، ظهور مفهوم سنتز سطح بالا گام مهم دیگری در جهت کاهش پیچیدگیهای طراحی و همچنین افزایش بهره وری سیستمهای دیجیتال بود. در واقع HLS پلی است میان سخت افزار و نرم افزار که با تمرکز زدایی از سخت افزار و بکارگیری زبانهای سطح بالا، راندمان طراحی را ارتقا میبخشد. در سالهای اخیر سنتز سطح بالا به طور کلی قوانین بازی را تغییر داده است و با ظهور HLS کار توسعه الگوریتمها برای تراشههای قابل پیکرهبندی به شکل کامل متحول شده است. در این سری دو قسمتی از پایگاه دانش هگزالینکس قصد داریم برخی از مهمترین نکات و تکنیکهای طراحی با Vivado HLS را با هم مرور کنیم و با بیان مثالهای کاربردی قدرت پنهان HLS را برای شما به نمایش بگذاریم.
نکات و تکنیکهای طراحی
ابزار Vivado HLS و به طور کلی مفهوم سنتز سطح بالا به ما طراحان کمک میکند که کارمان را در سطح انتزاعی بالاتری اجرا کنیم. علاوه بر این زمان صحه گذاری و ارزیابی عملکرد طرح را نیز به شکل چشمگیری کاهش میدهد. دلیل این کاهش نیز استفاده از قابلیت شبیه سازی C است. در کنار شبیه سازی C ، شبیه سازی RTL نیز با استفاده از تست بنچ نوشته شده به زبان C برای شبیه سازی توأمان RTL در فازهای پایانی توسعه قابل اجرا خواهد بود.
شبیه سازی
در Vivado-HLS تست و صحه گذاری کدهای C با استفاده از test bench نوشته شده به زبان C انجام میشود. این شبیه سازی تحت عنوان c-based simulation یا به بیان فارسی شبیه سازی C نام گذاری شده است.
عبارت C/RTL Co-simulation معرف شبیه سازی توامان سخت افزاری و نرم افزاری است. در واقع برنامه test bench نوشته شده به زبان C به صورت اتوماتیک به RTL test bench تبدیل میشود و امکان فراخوانی و اجرای آن در Vivado امکان پذیر میگردد. این شبیه سازی که روی طرح RTL خروجی اجرا میشود، تحت عنوان co-simulation نام گذاری شده است. در طول این آموزش و به طور کلی کلیه آموزشهای HLS ما به اختصار عبارت شبیه سازی RTL را برای مخاطب قرار دادن این مفهوم استفاده میکنیم. تست و صحه گذاری کدهای C نیز با عنوان شبیه سازی C مخاطب قرار داده میشود.
در بخش اول این آموزش ما قصد داریم با نگاهی موشکافانه به قابلیتهای ابزار Vivado HLS ، روش ساخت یک بلوک IP برای الگوریتمهای پردازش سیگنال را بررسی کنیم. در طول فرایند ساخت IP نیز نکات و تکنیکهای کاربردی طراحی با Vivado HLS برای دستیابی به نتایج مطلوب و بهینه را با هم مرور کنیم. مواردی همچون:
- تعریف یک رویکرد مناسب برای پیاده سازی الگوریتم مطلوب
- تعریف اینترفیس مناسب برای اپلیکیشنها
- بهینهسازی ظرفیت خروجی (throughput) و پایپلاینینگ (pipelining)
- درک ساختارهای متفاوت بلوکهای حافظه block RAM
- کار با سیستمهای اعداد ممیز ثابت و انواع Arbitrary Precision
پیش از آغاز طراحی، اولین چیزی که نیاز است بدانیم، تعریف صحیح مسألهای است که قرار است حل کنیم. در این مطلب ما یک مثال عملی را با هم حل میکنیم. اگر تجربه کار با سیستمهای صنعتی را داشته باشید، احتمالاً با این چنین مثالهایی روبرو شدهاید. این مثال در بسیاری از اپلیکیشنهای کنترلی و صنعتی کاربرد دارد.
تعریف مسأله
مانیتور کردن مداوم دمای سیستم در فرایندهای صنعتی کاری مرسوم و البته ضروری است. این کار غالباً با استفاده از ترمیستور thermistor و یا ترمومتر thermometer که ادوات اندازه گیری دما هستند، انجام میشود. هر دو این ادوات غیرخطی هستند و با توجه به تغییرات مقاوت دمای سیستم را گزارش میکنند. در هر دو قطعه، برای اینکه مقدار صحیح دما با توجه به مقدار مقاومت اندازه گیری شده تعیین شود، باید یک تبدیل انجام دهیم.
از بین ترمیستور و ترمومتر، رابطه تبدیل برای دما در ترمومترها کمی پیچیدهتر است. این رابطه به نام معادله Callendar-Van Dusen شناخته میشود و اولین بار در سال ۱۹۲۵ توسط دانشمندی به همین نام منتشر شد.
فرم کوتاه این معادله تبدیل به صورت رابطه زیر است، در این رابطه مقدار مقاومت R بر حسب دمای t بیان شده است.
\[R=R_0\times(1+a+t+b+t^2)\]
خب در همین ابتدای کار به نظر میرسد کمی با این رابطه مشکل داریم. چون به صورت طبیعی، در کاربردی که مد نظر ماست، تمایل داریم این رابطه را به صورت برعکس مورد استفاده قرار دهیم. یعنی مقدار دما را برحسب مقاومت بدست آوریم. بنابراین ما میتوانیم رابطه بالا را به صورت رابطه زیر بازنویسی کنیم.
\[t=\frac{-R_0\times a + \sqrt {{R_0}^2\times a^2 -4\times R_0\times b \times(R_0-R)}}{2\times R_0 \times b}\]
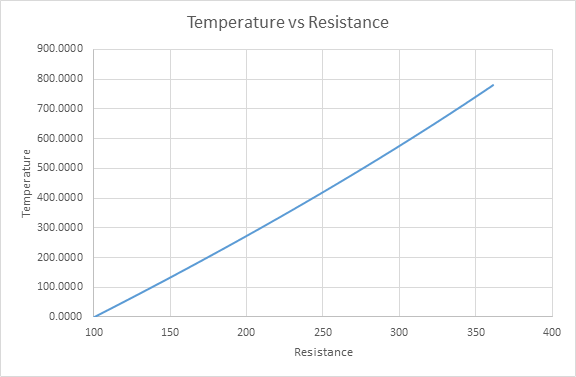
با وجود اینکه پیادهسازی رابطه بالا امکان پذیر است، اما بدون شک پیادهسازی آن چه با HDL و چه با HLS کار پیچیدهای است. موافقید؟
رویکرد جایگزین برای پیادهسازی ساده تر رابطه Van Dusen ، پیادهسازی یک چند جملهای به جای آن است. در واقع این چند جملهای یک منحنی است، که باید با دقت مطلوبی رابطه اصلی را تقریب بزند (فیت کردن یک منحنی ساده تر به منحنی پیچیده بالا). این دقیقاً همان کاری است که سعی داریم در این مثال انجام دهیم.
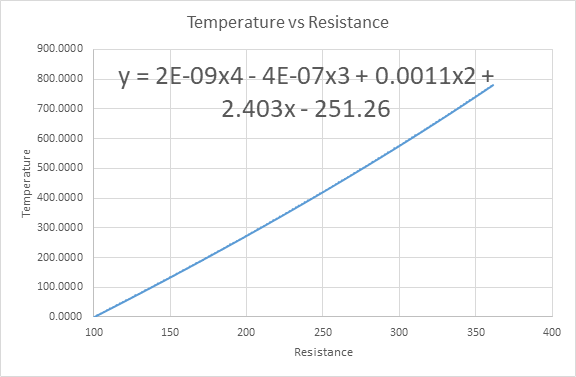
رابطه زیر یک تقریب غیرخطی از رابطه Van Dusen است. که در آن y معادل زمان و x معادل مقاومت است. پس رابطهای که برای پیاده سازی استفاده خواهیم کرد یک چند جملهای درجه ۴ خواهد بود.
\]y=2e^{-9}x^4-4e^{-7}x^3+0.0011x^2+2.403x-251.26\]
ساخت پروژه
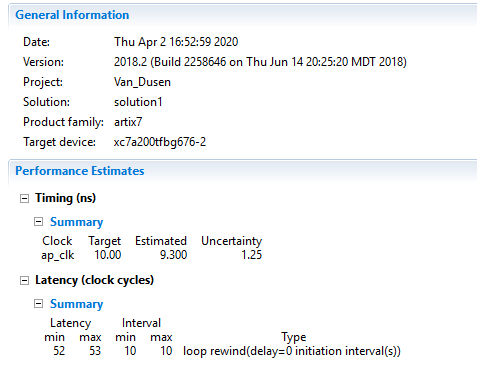
خب حالا که در رابطه با نحوه پیاده سازی رابطه بین دما و مقاومت تصمیم گیری کردیم، گام بعدی اجرای نرم افزار Vivado HLS و ساخت یک پروژه جدید است. من در این پروژه از نسخه 2018.2 ابزار Vivado HLS استفاده میکنم. شما میتوانید از هر نسخهای که در اختیار دارید استفاده کنید. با توجه به اینکه از چه تراشهای استفاده میکنید ممکن است نتایج شما با نتایجی که من بدست میآورم کمی متفاوت باشد، که این خودش یکی از ویژگیهای ابزار Vivado HLS است. من از بزرگترین تراشه خانواده Artix یعنی xc7a200tfbg676-2 روی بورد AC701 استفاده میکنم. چون در نهایت پروژه را روی سخت افزار تست نمیکنیم پس نگرانی در این رابطه نداریم.
سورس فایلها
ابتدا درون پروژه، ما سه فایل جدید میسازیم. دو فایل با پسوند cpp به عنوان سورس فایلهای اصلی پروژه و یک فایل هدر با پسوند hpp، به صورت زیر:
- فایل ++C برای پیاده سازی الگوریتم تحت عنوان cvd.cpp
- فایل ++C به عنوان testbench برای شبیه سازی عملکرد الگوریتم تحت عنوان cvd.hpp
- فایل ++C به عنوان کتابخانه برای تعریف فانکشنهای شتاب دهنده تحت عنوان cvd_tb.cpp
مشابه هر فایل دیگری که به زبان C مینویسیم در HLS نیز میتوانیم کل رابطه بالا را در یک خط و صد البته با استفاده از متغیرهای ممیز شناور بنویسیم. البته در رابطه با پیاده سازی ممیز ثابت و ممیز شناور در بخش دوم این مقاله بیشتر صحبت خواهیم کرد. اما کدی که من در اینجا استفاده میکنم به شکلی نوشته شده است، که در آن میتوانم با یک انتخاب ساده محاسبه یک یا چند مقدار را به صورت همزمان انجام دهم. برای این اپلیکیشن پردازش را روی یک دسته ده تایی انجام میدهیم و همه خروجیها را همزمان تولید میکنیم. یعنی هر بار یک آرایه ۱۰ تایی از x را میگیریم و بعد از پردازش ۱۰ مقدار برای y تولید میکنیم. به نوعی یک فریم بندی خیلی ساده روی داده های ورودی و خروجی قرار دادهایم.
برای تست عملکرد سیستم کار سختی نداریم، کافیست یک کد متلب ساده بنویسیم و با دادههای تصادفی عملکرد کدهای HLS را با کدهای Matlab مقایسه کنیم. از این رو از توضیح اضافی در مورد کد cvd_tb.cpp خودداری میکنیم. بهتر است خودتان این کار را انجام دهید تا کمی دستتان گرم شود. در صورت نیاز سوال هایتان را در انتهای همین پست با ما در میان بگذارید.
// copyright 2020 Hexalinx.com
// cvd.cpp
#include "cvd.hpp"
#include <math.h>
using namespace std;
void cvd(float x[size], float y[size]) {
int i;
cvd_loop: for (i = 0; i < size; i++) {
y[i] = a * powf(x[i], 4) - b * powf(x[i], 3) + c * powf(x[i], 2) + d * x[i] - e;
}
}
// copyright 2020 Hexalinx.com
// cvd_tb.cpp
#include "cvd.hpp"
#include <stdio.h>
using namespace std;
int main() {
int i;
float test[size]={100.0,95.0,90.0,85.0,80.0,75.0,70.0,65.0,60.0,55.0};
float golden[size]={-0.1600,-13.2275,-26.2404,-39.1987,-52.1029,-64.9530,-77.7492,-90.4916,-103.1805,-115.8157};
float result[size];
float error;
cvd(test, result);
test_loop: for (i = 0; i < size; i++) {
printf("result = %f golden = %f,\r\n", result[i], golden[i]);
error += result[i] - golden[i];
}
if (error < 0.01){
printf("passed! error = %f \r\n", error);
return 0;
}
else{
printf("failed! error = %f \r\n", error);
return 1;
}
}
// copyright 2020 Hexalinx.com // cvd.hpp const int size = 10; const float a=2e-9; const float b=4e-7; const float c=0.0011; const float d=2.403; const float e=251.26; void cvd(float*, float*);
سنتز کدهای C
بعد از فراخوانی و اجرای عملیات سنتز روی کدهای C (کافی است از نوار ابزار بالا گزینه C Synthesize را انتخاب کنید)، ملاحظه خواهید کرد که برای آرگومانهای X و Y فانکشن ما به صورت اتوماتیک از اینترفیسهایی که با استفاده از بلوکهای حافظه پیاده سازی شدهاند، استفاده میکند. البته انتظار چنین چیزی را نیز داشتیم. با توجه به اینکه ما آرگومانها را به صورت آرایه تعریف کردیم، ورودی خروجیهای فانکشن در زمان سنتز بر روی سختافزار به صورت آرایه درون حافظه پیاده سازی میشوند.
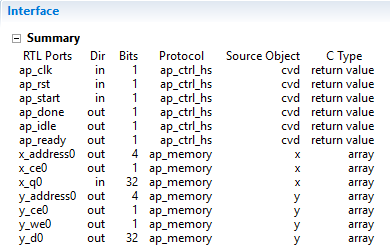
تعریف اینترفیسها
البته، از آنجایکه ما تنها دیتا را به فانکشن ارسال میکنیم (پورت یکطرفه ورودی)، احتمالاً استفاده از یک اینترفیس FIFO گزینه آسانتر و مناسب تری خواهد بود. بنابراین از دایرکتیو interface به شکل یک پراگما به صورت زیر استفاده میکنیم.
#pragma HLS interface ap_fifo port=x #pragma HLS interface ap_fifo port=y
در عمل با استفاده از گزینه ap_fifo در پراگمای اینترفیس، از بکارگیری یک FIFO به جای یک بلوک RAM بعد از سنتز اطمینان حاصل میکنیم.
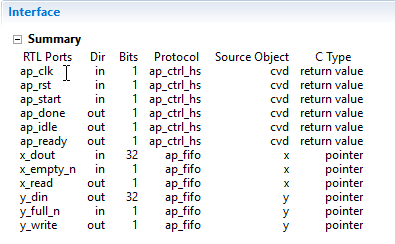
در صورتی که تمایل داشته باشیم، میتوانیم از اینترفیس AXI نیز استفاده کنیم. ما معمولاً این کار را زمانی انجام میدهیم که تمایل داشته باشیم IP نهایی ما با PS در تراشههای Zynq APSoC و یا Zynq MPSoC و یا دیگر IP هایی که دارای اینترفیس AXI هستند، کار کند.
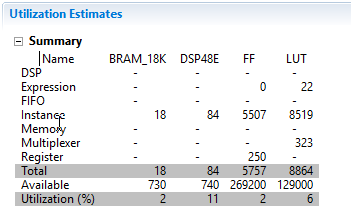
نکته دیگری که لازم است به آن توجه کنیم، کارایی طرح است. طرح اولیه ما بدون اینکه پایپلاین شود و یا حلقههای آن باز شوند سنتز شده است. در نتیجه برای پیاده سازی ۱۰ محاسبه، به حدود ۴۳۱ سیکل کلاک نیاز دارد. اما به سادگی میتوانیم با اعمال تمهیداتی عملکرد و راندمان بالاتری از این فانکشن بدست بیاوریم. اما چگونه؟ در ادامه با استفاده از چند دایرکتیو ساده این کار را انجام میدهیم.
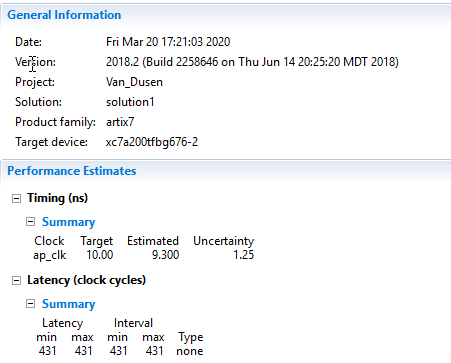
بهینه سازی با دایرکتیوها
در اولین گام با استفاده از دایرکتیو pipeline، میتوانیم ظرفیت خروجی فانکشن را بهبود بدهیم. این دایرکتیو هم روی حلقهها و هم روی فانکشنها قابل اعمال است. توجه داشته باشید که پایپلاین کردن حلقه بیرونی به صورت اتوماتیک باعث باز شدن (unroll) حلقههای داخلی میشود.
پایپلاینینگ باعث کاهش پارامتر initiation interval (II) فانکشنها میشود. پارامتر initiation interval (II) مشخص میکند که فانکشن چه زمانی میتواند پذیرای داده جدید روی ورودی برای پردازش باشد. بنابراین برای دستیابی به بالاترین کارایی و ظرفیت خروجی، سعی میکنیم پارامتر II را تا حد امکان کوچک کنیم.
// copyright 2020 Hexalinx.com
// cvd.cpp
#include "cvd.hpp"
#include <math.h>
using namespace std;
void cvd(float x[size], float y[size]) {
#pragma HLS INTERFACE ap_fifo port=x
#pragma HLS INTERFACE ap_fifo port=y
int i;
cvd_loop: for (i = 0; i < size; i++) {
#pragma HLS PIPELINE
y[i] = a * powf(x[i], 4) - b * powf(x[i], 3) + c * powf(x[i], 2) + d * x[i] - e;
}
}
ناگفته پیداست که پاپلاین کردن یک فانکشن باعث افزایش منابع مصرفی روی تراشه میشود. با توجه به اینکه ما در این مثال از متغیرهایی با نوع float استفاده کردیم، شرایط بدتر نیز میشود. نکتهای که بد نیست به آن اشاره کنم گزینه rewind در دایرکتیو pipeline است. با استفاده از این گزینه در تنظیمات پاپلاین میتوانیم تأخیرهای بین تکرارهای حلقهها را کاهش دهیم. توضیح دقیق این مسأله خارج از حوصله این مقاله است. از این رو از توضیح بیشتر در رابطه با گزینههای پیشرفته دایرکتیو pipeline صرف نظر میکنیم.
با وجود اینکه این مسأله در این مثال مصداق ندارد، اما بد نیست بدانید که در صورت داشتن چند تابع HLS که در تعامل با یکدیگر هستند، ما میتوانیم از دایرکتیو data_flow استفاده کنیم. با این دایرکتیو ما قادر خواهیم بود پایپلاینینگ را به جای حلقه در سطح فانکشنها اعمال کنیم و مرزهای بهینه سازی را بگسترانیم.
اگر ما علاوه بر آرگومانهای ورودی خروجی از ساختار حافظهها درون فانکشنهای خودمان استفاده کنیم در حقیقت بلوکهای حافظه FPGA را درون طرح خودمان فراخوانی و پیادهسازی میکنیم. حتماً به این نکته توجه داشته باشید که این بلوکهای حافظه با توجه به محدودیت اینترفیسها برای خواندن و نوشتن، ممکن است باعث ایجاد گلوگاه در طراحی شوند.
پارتیشن بندی آرایهها
بلوکهای حافظه در FPGA حداکثر دارای دو پورت هستند، از این رو امکان اجرای بیش از دو عملیات خواندن و یا دو عملیات نوشتن همزمان روی یک حافظه وجود ندارد. این محدودیت یک چالش مهم در زمان موازی سازی عملیات محاسباتی در HLS است و باید برای افزایش تعداد دسترسیهای همزمان به حافظه ملاحظات کافی در کد در نظر گرفته شود. در بسیاری از موارد استفاده مناسب از دایرکتیوها برای دستیابی به نتایج مطلوب کفایت میکند.
برای پاسخ به این چالش ما میتوانیم با استفاده از تکنیک پارتیشن بندی، نحوه ذخیره دیتا روی بلوکهای حافظه را مجدداً سازماندهی کنیم. به این ترتیب دادهها به صورت موثرتری برای شتابدهی ذخیره میشوند. با استفاده از دایرکتیو array_partition، ما میتوانیم به نحو مناسبی، حافظه مد نظرمان به چندین حافظه کوچکتر تقسیم (پارتیشن بندی) کنیم و چگونگی ذخیره سازی دیتا روی بلوکهای حافظه را کنترل کنیم.
در زمان استفاده از این دایرکتیو، باید با توجه به کاربرد مد نظرمان یکی از الگوهای زیر را برای پارتیشن بندی حافظه انتخاب کنیم. با توجه به شکل زیر آیا میتوانید تفاوتهای این سه الگوی متفاوت را بیان کنید و آنها را با هم مقایسه کنید؟
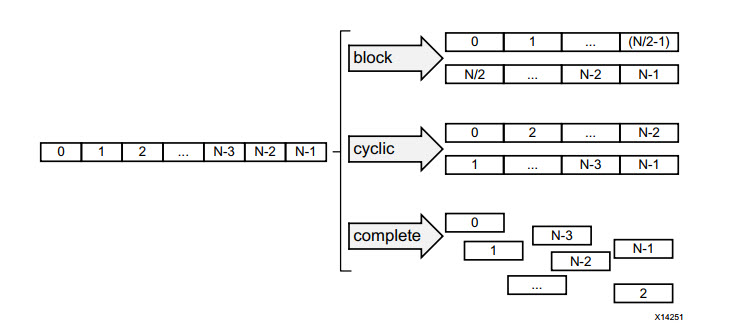
لازم به ذکر است که در صورت نیاز، میتوانیم از دایرکتیو array_reshape برای تجمیع یا ترکیب عناصر حافظه استفاده کنیم.
با رسیدن به این نقطه ما عملاً کار پیاده سازی یک معادله صنعتی نسبتاً ساده و پرکارد با HLS را به پایان رساندهایم، در حالت کلی میتوانیم از طراحی خودمان به عنوان بخشی از یک سیستم کاملتر درون FPGA استفاده کنیم. به هر حال ظرفیت خروجی (throughput) در این نقطه قابل قبول است و لازم نیست بیشتر از این کار را ادامه بدهیم.
جمع بندی
همانطور که ملاحظه کردید، ما در پیاده سازی خودمان از اعداد ممیز شناور و متغیرهایی از نوع float استفاده کردیم، استفاده از محاسبات ممیز شناور به شدت روی ظرفیت خروجی و منابع مصرفی تأثیر منفی میگذارد. روش بسیار موثرتر پیاده سازی یک solution دیگر با استفاده از اعداد ممیز ثابت است. در بخش دوم از این آموزش، ما نگاهی دقیقتر به این مسأله میاندازیم و چگونگی تبدیل یک کد ممیز شناور به کد ممیز ثابت را با استفاده از کتابخانه fixed point arbitrary precision بررسی میکنیم. خواهید دید که با رعایت نکات و تکنیکهای طراحی در Vivado HLS و استفاده از متغیرهای ممیز ثابت نتایج به مراتب بهتری کسب خواهیم کرد.
منبع: با اقتباس از hackster.io نوشته Adam Taylor






6 در مورد “نکات و تکنیکهای طراحی با Vivado HLS (بخش اول: پیاده سازی ممیز شناور)”
سلام ببخشید من دو تا سوال دارم: اول اینکه هر کد سی بهش بدهیم برامون کدش رو درست میکنه یا باید قالب خاصی داشته باشه؟
دوم اینکه باید براش به زبان سی هم تست بنچ بنویسم تا برامون تبدیلش کنه به hdl؟
سلام و و عرض ادب و احترام بر شما
بخش اول سوالتون خیلی پاسخ صریحی ندارد، در حالت کلی تعدادی ملاحظات محدود وجود دارد که با در نظر گرفتن آنها میتوان انتظار داشت که کدهای C روی FPGA سنتز بشوند، اما این بدین معنا نیست که سنتز کدها بهینه است و مدار تولیدی مطابق انتظار است. برای تولید یک مدار خوب و بهینه باید کدهای C مطابق با الگوهای HLS اصلاح شود.
پاسخ بخش دوم سوالتون هم بله است. شما باید تست بنچ C بنویسید، بعد از تست موفق کد C ابزار با استفاده از این تست بنچ بردارهای تست مورد نیاز در hdl را تولید میکند.
با سلام.
خیلی ممنون از مطالب خوبتون . بنده نرم افزار vivado hls را از سایت شما یاد گرفته ام.
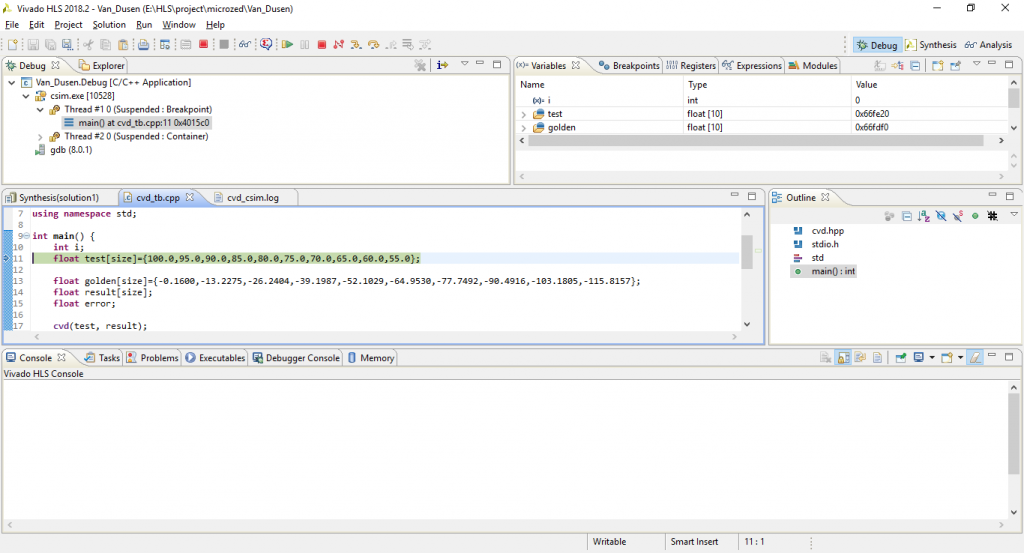
ولی سوالی داشتم. پس از سیمولیشن کدی که در بالا نوشتید در بخش دیباگ variable ها به صورت زیر تعریف میشوند. دلیل عدم تطابق انها با مقدار اصلی که در کد نوشته اید چیست؟
Name : test
Details:{1.40129846e-045, 0, 5.88685625e-039, 0, 5.60519386e-045, 0, 6.16571324e-044, 0, 5.92556432e-039, 0}
و یا Name : golden
Details:{5.88688848e-039, 0, 6.16571324e-044, 0, 4.5169791e-039, 0, 1.40129846e-045, 0, -nan(0x7fffff), -nan(0x7fffff)}
سعید عزیز روز بخیر
از اظهار لطفی که نسبت به هگزالینکس داشتید، سپاسگزاریم. امیدوارم همچنان پر انرژی در مسیر یادگیری و توسعه فردی گام بردارید.
با توجه به توضیحاتی که دادید به نظر میرسه قبل از اینکه شبیه سازی را به اندازه کافی اجرا کنید و یا اینکه در انتهای کار بعد از اتمام شبیه سازی مقدار متغیرها را بررسی کردید. اگر حدس من درست باشه باید خدمتتون عرض کنم که یک اشتباه کوچک مرتکب شدید. مقادیر متغیرها قبل از اینکه مقدار دهی بشوند کاملاً نا معتبر هستند. از این رو پیشنهاد میکنم یکبار دیگر با اینبار با کمی حوصله شبیه سازی را تکرار کنید و با استفاده از گزینه step in گام به گام در کد پیش برید. اگر دقیقاً بعد از مقدار دهی متغیرهای test و golden مقدارشون را بررسی کنید، متوجه خواهید شد که همه چیز درست هست.
سلام
وقت به خیر
سپاس از ارائه ی این مطالب
در مورد این ورژن ویودو، امکانش هست سایتی معرفی کنید؟
یا ورژن دیگری که محیطش منطبق با این محیط باشه؟
درود بر شما
متأسفانه دقیقاً متوجه سوأل شما نشدم!
ما برای این مقاله از نسخه 2018.2 ابزار Vivado HLS استفاده کردیم. خوشبختانه Xilinx در این مورد خیلی سخت گیر نیست و شما میتونید از هر نسخهایی که دارید استفاده کنید. و فقط فایلهای C رو به پروژتون اضافه کنید. از نسخه 2015.1 تا 2019.1 همگی قابل استفاده هستند.
تقریباً در نسخههای اخیر همه چیز مشابه و منطبق بر هم هست. دقیقاً کدام قسمت برای شما شکل ساز شده است؟