
مقدمه
آیا تا به حال به این فکر کردهاید که یک تابع منطقی مانند f = x1 and x2 در FPGA به چه صورت پیادهسازی میشود؟ آیا به نظر شما در FPGA گیت AND ، OR یا هر نوع گیت دیگری برای اینکار وجود دارد؟ و اگر وجود دارد این گیتها کجا هستند؟ آیا تا به حال نام بلوکهای منطقی قابل پیکرهبندی را شنیدهاید؟
در پاسخ به این سوال باید گفت، خیر. در FPGA گیتهای مجزا برای این نوع عملیات منطقی و حتی عملیات منطقی پیچیدهتر وجود ندارد. در عمل بلوکهای منطقی قابل پیکرهبندی یا همان CLB ها وظیفه اصلی پیادهسازی توابع منطقی با هر نوع پیچیدگی را بر عهده دارند. در این آموزش از پایگاه دانش هگزالینکس به شکلی دقیقتر ساختار داخلی CLB ها را مرور میکنیم. همینطور نحوه پیادهسازی توابع منطقی با استفاده از این بلوکها را بررسی میکنیم. در انتها نیز نحوه بکارگیری آنها برای ساختن یک حافظه را بررسی میکنیم.
معرفی بلوکهای منطقی قابل پیکرهبندی
مطالبی که خدمتتان ارائه میگردد، با توجه به معماری تراشههای سری ۷ و خانواده اسپارتان ۶ تهیه شده است. معماری بلوکهای منطقی قابل پیکرهبندی در سایر تراشههای Xilinx تا حدودی متفاوت است، اگر چه شباهتهایی نیز دارند. تراشههای FPGA شرکت Xilinx دارای تعداد زیادی بلوک CLB هستند. هر کدام از CLB ها متشکل از دو اسلایس هستند. هر اسلایس نیز شامل ۴ عدد LUT شش ورودی، ۸ عدد فلیپ فلاپ، یک زنجیره بیت نقلی و تعدادی مالتی پلکسر عریض است. ساختار داخلی یک LUT به صورت شکل (۱) است.
هر بلوک منطقی قابل پیکرهبندی، متشکل از دو اسلایس هست.
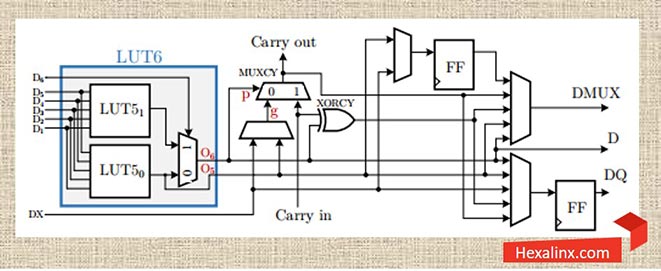
همانطور که در شکل (۱) میبینیم، هر LUT داری شش ورودی مستقل به نام های D1 تا D6 و دو خروجی مستقل به نام های O5 و O6 میباشد. هر LUT قابلیت پیادهسازی یک تابع شش ورودی با هر نوع پیچیدگی را دارد. مثلا تابع f را به صورت زیر در نظر بگیرد.
f=((D1 and D2) or (D3 and not (D4 or D5)) and D6)
با یک مرور کوتاه به درس مدار منطقی به یاد میآوریم که یک جدول درستی با شش ورودی میتوانست ۶۴خروجی مختلف داشته باشد. در حقیقت LUT ها در FPGA کاملا مشابه جداول درستی با شش ورودی عمل میکنند. علاوه بر این هر LUT میتواند مشابه یک حافظه با ۶۴ عنصر حافظه نیز عمل کند. هنگام پیادهسازی یک تابع شش ورودی، ابتدا جدول درستی این تابع توسط ابزار سنتز در ISE و یا Vivado ساخته میشود. سپس تابع خروجی روی LUT ها نگاشت میشود و در نهایت روی تراشه پیکرهبندی میشود.
جزئیات LUT های شش ورودی
نکته مهمی که باید به آن اشاره کرد این است که یک LUT شش ورودی میتواند همانند دو عدد LUT مستقل پنج ورودی نیز مورد استفاده قرار بگیرد. البته این پنج ورودی بین هر دو LUT مشترک هستند. هر LUT میتواند جدول درستی اختصاصی خودش و البته خروجی اختصاصی خودش یعنی O5 یا O6 را داشته باشد. در حالتی که تابع مورد نظر برای پیادهسازی نیاز به استفاده همزمان از هر دو LUT داشته باشد، یک LUT شش ورودی ساخته میشود و تنها خروجی O6 استفاده میشود. در صورت استفاده تکی از LUT ها هر دو خروجی بکار گرفته میشوند.
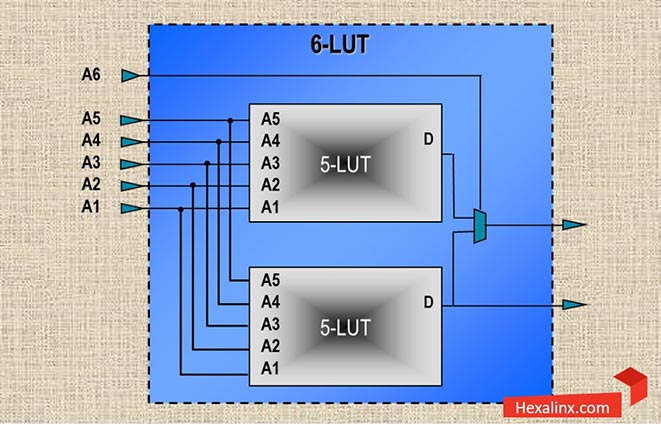
استفاده ار LUT به عنوان حافظه
هر LUT میتواند در نقش یک حافظه ROM یا RAM جهت ذخیره سازی ۶۴ عدد تک بیت یا ۳۲ عدد دو بیتی استفاده شود. در اینجا هم در حالت اول فقط خروجی O6 و در حالت دوم هر دو خروجی O5 و O6 به صورت همزمان استفاده میشوند. توجه داشته باشید هنگامی که تعداد محدودی عدد چند بیتی (مثلا ۱۲۸عدد تک بیتی) در یک ROM ذخیره میکنیم، در صورت کدنویسی صحیح (تاکید میکنم، حتما باید ساختار کد صحیح باشد) ابزار سنتز به صورت اتوماتیک از LUT ها جهت این کار استفاده میکند و به نوعی یک حافظه توزیع شده سنتز میشود ولی اگر تعداد اعداد از یک حدی بیشتر باشند، حافظه ROM ما به بلوکهای حافظه داخلی نگاشت میشود. تعیین آستانه برای انتخاب بین یک حافظه توزیع شده یا بلوکهای حافظه به موارد متعددی بستگی دارد.
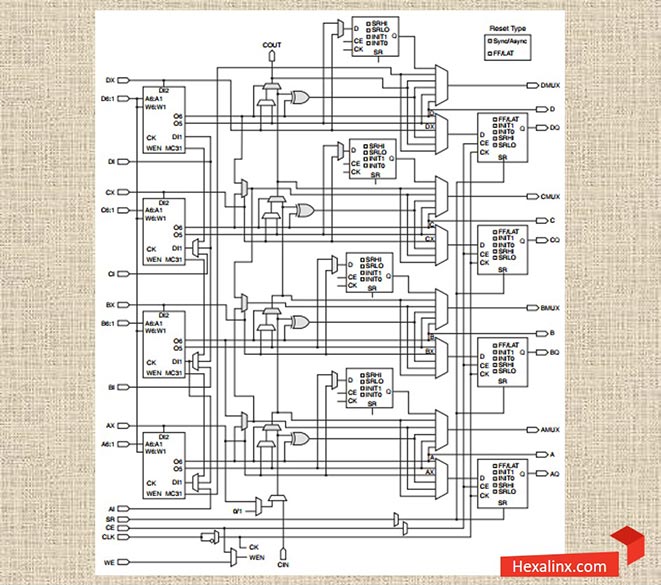
با ترکیب هر چهار LUT درون یک اسلایس میتوان حافظههای بزرگتری با ظرفیت حداکثر ۲۵۶بیت بدون استفاده از هیچ نوع منابع اضافی روی تراشه فراخوانی کرد. همانطور که در شکل (۳) نشان داده شده است، درون هر اسلایس سه مالتی پلکسر عریض با نامهای F7AMUX ، F7BMUX و F8MUX وجود دارد که برای ترکیب کردن خروجی LUT ها و ساخت حافظه های ۱۲۸ و ۲۵۶ بیتی مورد استفاده قرار می گیرند. وجود این مالتی پلکسرهای عریض به طراح اجازه می دهد تا با ترکیب کردن LUT ها توابع منطقی با ۷ و یا ۸ ورودی را نیز به راحتی درون یک اسلایس طراحی کند. نام گذاری مالتی پلکسرهای عریض با توجه به تعداد ورودیهای آنها صورت گرفته و عناصر بسیار مهمی در طراحی هستند.
زنجیره بیت نقلی
بحث در رابطه با CLB ها هنوز به پایان نرسیده، عملکرد CLB ها در انجام عملیات ریاضی و به خصوص تاثیر زنجیره بیت نقلی در افزایش کارایی مدار بسیار حائز اهمیت است. در ادامه نحوه پیادهسازی یک جمع کننده را با استفاده از منابع درون CLB بررسی میکنیم، توجه داشته باشید که عملیات جمع در کدنویسی Verilog و VHDL با عملگر + انجام میشود. اما مفهومی که در ادامه آموزش داده میشود نحوه نگاشت یک جمع کننده به CLB های درون تراشه است. آگاهی از این مساله باعث میشود، طراح کنترل بهتری روی منابع مصرفی روی تراشه داشته باشد.
از درس مدار منطقی بیاد داریم که یک جمع کننده n بیتی نیاز به n بلوک جمع کننده کامل دارد. یک جمع کننده کامل دو ورودی a و b را با ورودی نقلی cin جمع میکند و خروجی جمع sout و cout را تولید می کند. با فرض اینکه
P = a xor b
آنگاه برای sout و cout داریم:
sout = (a xor b) xor cin = (p xor cin)
cout = (a and b) or (a xor b) and cin = (a and b) or (p xor cin)
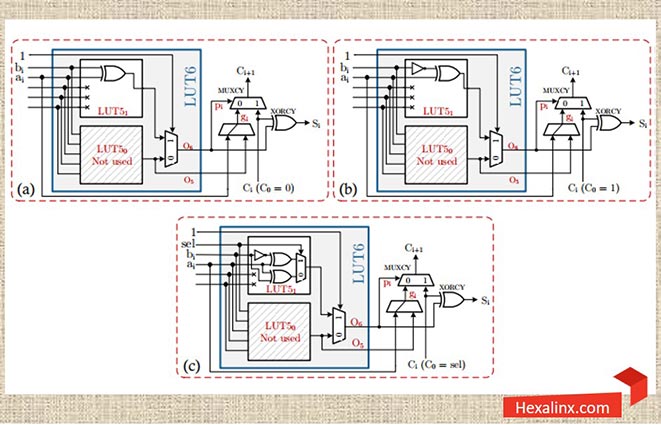
در شکل (۴) نحوه پیادهسازی یک جمع کننده کامل با استفاده از یک LUT و زنجیره نقلی اطراف آن نشان داده شده است. واضح است که برای انجام یک جمع n بیتی، لازم است n بلوک کنار هم قرار بگیرند و خروجی نقلی i-ام به ورودی نقلی i+1-ام متصل شود. ضمنا ورودی نقلی اولین جمع کننده کامل صفر است. سوالی که مطرح میشود این است که علت قرار دادن زنجیره بیت نقلی در CLB ها بلافاصله بعد از LUT ها چیست؟ پیشتر اشاره کردیم که هر LUT دو خروجی مستقل O5 و O6 دارد که میتوانند همزمان دو تابع پنج ورودی با ورودیهای مشترک را پیادهسازی کنند. خب چرا مقدار cout با یکی از خروجیهای این LUT ها تولید نمیشود؟
هدف اصلی از قرار دادن زنجیره بیت نقلی در CLB ها مشارکت در عملیات جمع است.
شکستن مسیر بحرانی
پاسخ به این سوال را باید در بحث مسیرهای بحرانی جستجو کرد، اگر با مسیرهای بحرانی آشنا نیستید، لازم نیست نگران باشید، به زبان ساده مسیرهای بحرانی به طولانیترین مسیرهای موجود روی تراشه اطلاق میشود. این مسیرهای طولانی باعث افزایش تاخیر انتشار و در نتیجه کاهش سرعت و کارایی مدار میشوند، کنترل این مسیرها یک تکنیک بسیار مهم در طراحی و از الزامات یک پیادهسازی خوب است. پس اجازه بدهید به بحث اصلی برگردیم و پاسخ را کمی بیشتر توضیح بدهیم.
در عمل زنجیره بیت نقلی برای بالابردن سرعت محاسبات مورد استفاده قرار میگیرد، به لطف وجود زنجیره نقلی برای یک جمع کننده n بیتی، از n عدد LUT که به صورت ستونی زیر هم قرار گرفته اند، استفاده می شود. مسیر بحرانی این مدار برابر با طول زنجیره نقلی می شود که خروجی cout را تولید می کند. واضح است که تاخیر جمع کننده در این حالت به شدت کاهش می یابد و مدار حاصل می تواند در فرکانس های بسیار بالا کار کند، حتی در مواردی که جمع کننده های بزرگ هم نیاز داشته باشیم بازهم کارایی مدار بسیار بالا خواهد بود.
در صورتی که زنجیره نقلی وجود نداشت و از LUT ها جهت تولید cout استفاده می شد، تاخیر نقلی خروجی ناشی از n عدد LUT بعلاوه مسیرهای routing مورد نیاز برای برقراری ارتباط بین آن ها بسیار زیاد می شد و با افزایش تعداد بیت ها فرکانس و کارایی مدار به شدت افت می کرد.
جمع بندی
در این مقاله به شکل خلاصه شما را با کارکرد بلوکهای منطقی قابل پیکرهبندی آشنا کردیم و معماری داخلی آنها را باهم مرور کردیم. لازم است این نکته را یادآوری کنم که عدم آگاهی نسبت به معماری و کارکرد CLB ها خدشهایی به کارکرد مدار وارد نمیکند و در بسیاری از موارد ابزار سنتز به کمک طراح میآید و اجازه میدهد بخشی از پیچیدگیهای سخت افزاری از دید کاربر پنهان باقی بماند. اما در مواردی که با محدودیتهای پیادهسازی به لحاظ سرعت و منابع مصرفی روبرو باشیم، باید با دقت بیشتری برای استفاده بهینه از معماری داخلی تراشهها کد نویسی کنیم.






2 دیدگاه برای “بلوکهای منطقی قابل پیکرهبندی، مهمترین عنصر پیادهسازی”
واقعا ازتون بابت به اشتراک گذاشتن اطلاعات ارزشمندتون ممنونم.
ممنون بابت بازخوردتون