
مقدمه
الگوریتمهای پردازش سیگنال غالباً بر اساس اجرای متوالی عملیات ضرب و جمع/تفریق پایه ریزی شدهاند. سه عملیات جمع، تفریق و ضرب در زبان VHDL از پیش تعریف شده هستند، یعنی یک مهندس طراح برای پیادهسازی مدار جمع، تفریق و یا ضرب نیازی به طراحی یک مدار اختصاصی با استفاده از دانشهای فراگرفته شده در درس مدار منطقی ندارد و فقط کافی است به ترتیب از عملگرهای + ، – و * استفاده کند. به این ترتیب ابزار سنتز، مدار مناسبی را درون FPGA برای هر عملگر پیادهسازی میکند. در صورتی که هر کدام از عملگرهای + ، – و * در کدهای VHDL فراخوانی شوند، ابزار سنتز دو گزینه برای پیاده سازی آنها دارد. (۱) استفاده از منابع منطقی درون تراشه یا CLB ها و (۲) استفاده از بلوکهای DSP48.
اینکه کدام گزینه انتخاب میشود به تنظیمات ابزار سنتز و تا حدودی شیوه کدنویسی مهندس پیاده ساز بستگی دارد و در مقالههای آتی در این رابطه بیشتر صحبت خواهیم کرد، اما در این مقاله از پایگاه دانش هگزالینکس به شکل اختصاصی در رابطه با تاریخچه و معماری داخلی بلوکهای DSP48 در تراشههای FPGA بحث خواهیم کرد. در انتها نیز روشهای مختلف فراخوانی این بلوکها درون طرح RTL را توضیح خواهیم داد.
تاریخچه بلوکهای DSP48
هدف اولیه Xilinx از قرار دادن یکسری بلوک سخت افزاری اختصاصی به نام DSP48 Slice در تراشههای FPGA افزایش قابلیتهای پردازش سیگنال این تراشهها در کنار توان اجرایی عملیات منطقی آنها بود. همزمان با توسعه تراشههای FPGA ضرب کنندههای ساده در تراشههای قدیمی Spartan-3 و Virtex-2 با DSP48 Slice ها جایگزین شدند و روز به روز نیز کارامدتر شدند. با ظهور تراشههای پر قدرت تر فانکشنالیتی این بلوکها نیز افزایش پیدا کرد، در واقع هم توان انجام عملیات منطقی و هم توان اجرای عملیات ضرب و جمع مورد نیاز در الگوریتمهای پردازش سیگنال در FPGA ها بهبود یافت.
در ادامه همراه با شما نگاهی به تفاوتها و شباهتهای بلوکهای DSP48 در نسلهای مختلف تراشههای FPGA شرکت Xilinx خواهیم داشت. در ابتدای کار ویژگیهای برجسته نسلهای اول را با جزئیات بیشتری توضیح میدهیم و هر چه که جلوتر میرویم با اختصار بیشتر به ذکر تفاوتها و ویژگیهای جدید بلوکهای DSP48 خواهیم پرداخت. به این ترتیب یک دید کلی از مسیری که برای دستیابی به بلوغ فعلی طی شده است، به شما ارائه میدهیم.
تراشههای Virtex-4
بلوکهای سخت افزاری DSP برای اولین بار سال ۲۰۰۴ در تراشههای Virtex-4 شرکت Xilinx معرفی شدند. در آن زمان هدف اصلی از اضافه شدن این بلوکهای سخت افزاری به معماری تراشههای FPGA افزایش قابلیتهای پردازش سیگنال FPGA بیان شد. معماری آنها در تراشههای Virtex-4 به شکلی است که یک زوج DSP48 Slice در کنار هم یک عنصر پردازشی به نام XtremeDSP را شکل میدهند. جزئیات این معماری در شکل زیر نشان داده شده است.
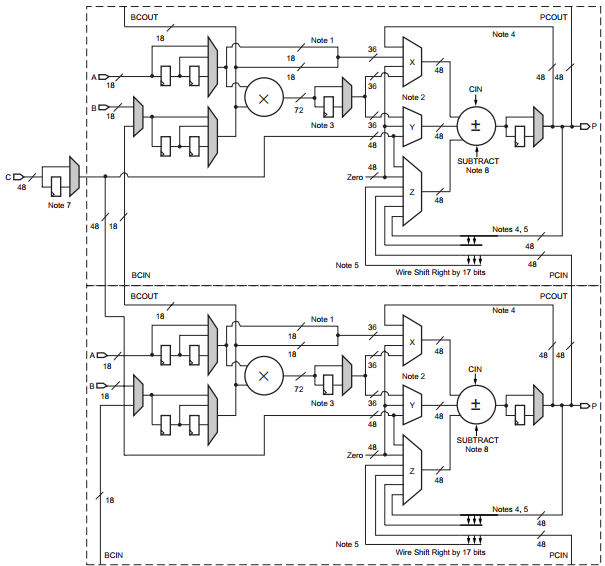
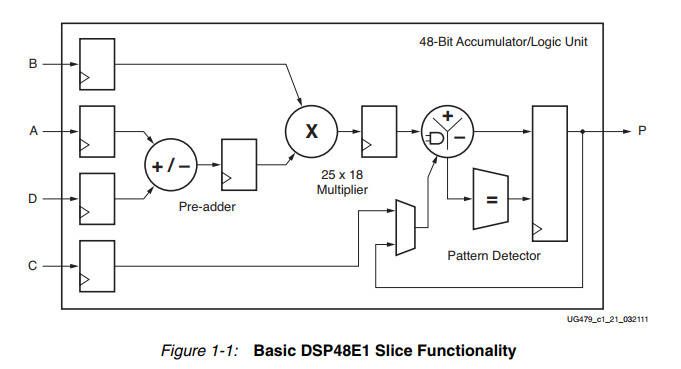
در اولین نگاه به یک DSP48 Slice ، یک ضرب کننده مکمل دو ۱۸×۱۸ بیتی مرکزی و یک جمع کننده/تفریق کننده/جمع کننده انباره ۴۸ بیتی جلب توجه میکند. دقیقاً همان فانکشنالیتی که به شکل گسترده در اکثر الگوریتمهای پردازش سیگنال مورد نیاز است. نگاه دوم به DSP48 Slice جزئیات بیشتری را نمایان میکند، ویژگیهایی که کارایی، تنوع و سرعت اجرای محاسبات این بلوکهای پردازشی را به شکل قابل توجهی افزایش میدهند.
رجیسترهای پایپلاین روی پورتهای ورودی، خروجی ضرب کننده و خروجی جمع کننده کارایی بالای DSP48 Slice ها را تضمین میکنند و طول بیت ۴۸ بیتی جمع کننده خروجی عملاً از بروز سرریز در جمعهای متوالی جلوگیری میکند.
یکی از مهمترین ویژگیهای XtremeDSP Slice ها در تراشههای Virtex-4 امکان اتصال آبشاری خروجی یک بلوک به ورودی بلوک مجاور بدون استفاده از منابع و مسیرهای همه منظوره داخلی تراشه است. این ویژگی امکان انجام جمعهای متوالی عریض را مشابه آنچه در فیلترهای FIR مورد نیاز است، فراهم میآورد.
ویژگی مهم دیگر این بلوکهای پردازشی، که بازهم در هنگام پیاده سازی فیلترها خودنمایی میکند، قابلیت اتصال آبشاری ورودی B یک DSP48 Slice به ورودیهای DSP48 Slice مجاور است.
وجود پورت C در DSP48 Slice ها امکان انجام توابع ریاضی با سه ورودی را نیز مهیا میکند. محاسبه حاصل جمع سه عدد یا ضرب دو عدد و جمع حاصلضرب آن با یک عدد سوم نمونهای از این محاسبات هستند.
و در نهایت پشتیبانی از عملیات شیفت به راست آخرین ویژگی کلیدی است که میتوان به آن اشاره کرد.
در معماری بلوکهای DSP48 مالتی پلکسرهای طوسی رنگ با توجه به تعداد طبقات پایپلاینی که برای اجرای محاسبات استفاده میشود به صورت اتوماتیک برنامه ریزی میشوند. سه مالتی پلکسر X و Y و Z هم با توجه با فانکشنالیتی مد نظر طراح توسط یک پورت کنترلی قابل برنامه ریزی هستند.
به شکل خلاصه این بلوکها قادر به پشتیبانی از محاسبات مختلفی همچون، ضرب کننده، ضرب و جمع کننده انبارهای (Multiply Accumulate – MACC)، جمع کننده سه ورودی، شیفت دهنده متغیر با مدارات ترکیبی (Barrel Shifter)، مقایسه کننده، شمارنده و مالتی پلکسر میباشند. البته جزئیات زیادی در رابطه با فانکشنالیتی و تنوع محاسبات قابل اجرا روی DSP48 Slice ها وجود دارد که ذکر تمام آنها امکان پذیر نیست و لازم برای تسلط پیدا کردن به آن ها به سند UG073 مراجعه کنید. در ادامه کمی در مورد نحوه عملکرد این بلوکها صحبت خواهیم کرد.
منابع متصل کننده
علاوه بر بلوکهای قابل پیکرهبندی (CLBs)، حافظهها (BRAMs)، بلوکهای ضرب کننده پردازش سیگنال (DSPs) و منابع ورودی و خروجی (IOs) که منابع مرسوم و مشترک درون تمامی تراشههای FPGA هستند، این تراشهها دارای منابع بسیار مهم دیگری به نام منابع متصل کننده یا Interconnect Resources یا Interconnect Switch Matrix هستند. این منابع به صورت یک شبکه ماتریسی قابل برنامه ریزی وظیفه برقراری ارتباط بین ورودی/خروجیها، و به طور کلی تمامی عناصر موجود درون تراشه را بر عهده دارند. این منابع در سر مسیرهای ارتباطی (routes) بین بلوکهای مختلف قرار گرفتهاند و گام جانمایی و مسیریابی (Place and Route) در فرایند پیاده سازی در واقع به برنامه ریزی و بهینه سازی نحوه اتصال مسیرها به منابع متصل کننده اختصاص دارد. کنترل جزئیات فرایند routing به شکل کامل در اختیار ابزارهای پیاده سازی است، البته کاربر میتواند با اعمال قیود مناسب کمی آن را سفارشی سازی کند، هر چند چندان توصیه میشود.
نکته جالب اینجاست که این منابع به طور متوسط بیش از ۶۰ درصد فضای درون FPGA را اشغال کردهاند و به نوعی جز پتنتهای شرکتهای سازنده FPGA محسوب میشوند. هر چه قدر این منابع بزرگتر و انعطاف پذیرتر باشند، امکان موفقیت در دستیابی به یک طراحی خوب افزایش مییابد. مضاف اینکه برخلاف چیزی که به نظر میرسد این منابع تأثیر به سزایی روی قیمت نهایی تراشه دارند در حالیکه کمتر به شکل مستقیم به آن اشاره میشود. به عنوان مثال عامل اصلی بالا بودن قیمت تراشههای Virtex در مقایسه با Kintex در خانواده سری ۷ در کنار افزایش منابع منطقی، پردازشی و همینطور فضای اشغال شده روی سیلیکون، بالا بودن تعداد اینترکانکتها است.
در مجموع Xilinx اعتقاد داشت با معرفی این واحدهای نسبتاً سطح بالای سخت افزاری، درون تراشههای FPGA گام بزرگی در تسهیل فرایند پیاده سازی الگوریتمهای پردازش سیگنال، چه به لحاظ کارایی و مصرف توان و چه به لحاظ حجم اشغال شده روی سیلیکون برداشته است. با توجه به توضیحاتی که تا به اینجا ارائه شد فلسفه قرار گرفتن عدد 48 در نام این واحدهای سخت افزاری روشن میشود که دلیل آن ۴۸ بیتی بودن خروجی نهایی DSP48 Slice هاست.
در ساده ترین شکل ممکن با توجه به شماتیک ساده شده DSP48 Slice در شکل زیر، محاسبات ریاضی قابل اجرا توسط آن را میتوان به شکل زیر خلاصه کرد. جایی که در آن خروجیهای سه مالتی پلکسر X و Y و Z با توجه به این رابطه در خروجی ظاهر میشوند.
Adder Out = (Z ± (X + Y + CIN))
به عنوان مثال اگر فرض کنید که میخواهیم دو عدد A و B را در هم ضرب کنیم و حاصل آن را به عدد C اضافه یا کم کنیم. در این صورت رابطه زیر با استفاده از تنها یک DSP48 Slice قابل پیاده سازی است.
Adder Out = C ± (A × B + CIN)
لیست کامل کلیه محاسباتی که توسط DSP48 Slice ها پشتیبانی میشوند در سند UG073 ارائه شده است.
تراشههای Virtex-5
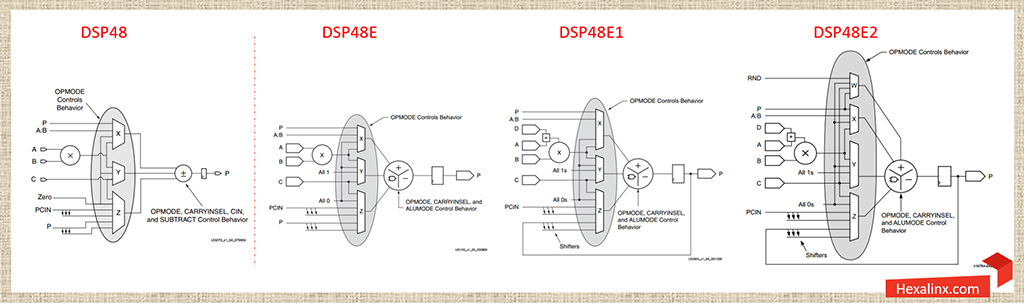
هر DSP48E Slice در خانواده تراشههای Virtex-5 نسخه بروز شده یک DSP48 Slice در خانواده تراشههای Virtex-4 است. این بلوکها تمام ویژگیها و قابلیتهایی را که در نسل قبلی وجود داشت به ارث بردهاند و البته قابلیتهای بیشتری نیز به آنها اضافه شده است. یکی از مهمترین ویژگیهایی که در DSP48E Slice معرفی شد، جایگزینی ضرب کننده مکمل دو ۱۸×۱۸ با ضرب کنندههای ۱۸×۲۵ بود، اما با این وجود DSP48E Slice ها در تراشههای Virtex-5 همچنان از نعمتی به نام پیش جمع کننده یا pre-adder بی بهره بودند.
عملیات ساده جمع و تفریق در DSP48E Slice های جدید به شکلی توسعه یافتند که امکان انجام تعداد محدودی عملیات منطقی نیز به آنها اضافه شد. بلوکهای پردازشی جدید در کنار ورودیهای نرمال A و B و C و مسیرهای آبشاری ورودی BCIN و PCIN یک ورودی آبشاری اضافی دیگر به نام ACIN نیز دارند. همینطور در کنار خروجی P و مسیرهای آبشاری خروجی PCOUT ، مسیر آبشاری خروجی ACOUT نیز به آنها اضافه شده است. همچون نسل قبلی این ورودی و خروجیهای آبشاری برای اتصال دو بلوک DSP48E Slice مجاور که در یک ستون قرار دارند، استفاده میشوند. در واقع با استفاده از این پورتها یک زنجیره پشت سرهم (cascaded chain) از DSP48E Slice ها شکل میگیرد که بدون اشغال مسیرهای ارتباطی معمول و اینترکانکتهای داخلی در تراشه های FPGA قادر تبادل اطلاعات با هم هستند.
تفاوت دیگری که در DSP48E Slice جلب نظر میکند، اختصاص یک پورت C اختصاصی به هر بلوک DSP48E است در حالی که قبلاً پورت C بین یک زوج DSP48 Slice مجاور به صورت مشترک استفاده میشد. البته بهینه سازیهای دیگری نیز روی این بلوکها اعمال شده است که در عمل چندان مورد استفاده قرار نمیگیرند. با توجه به شماتیک ساده شده DSP48E Slice رابطه خروجی جمع کننده انباره به صورت زیر قابل بیان است.
Adder/Sub Out = (Z ± (X + Y + CIN)) or (-Z + (X + Y + CIN) –1
در جدول اختصاصی که در راهنمای کاربری DSP48E Slice ارائه شده است، مقادیر کنترلی که باید به منظور فعال سازی یک فانکشنالیتی خاص روی هر کدام از مالتی پلکسرهای قابل پیکره بندی تنظیم گردد، به صراحت بیان شده است. برای اطلاعات بیشتر در رابطه با معماری داخلی XtremeDSP ها و نحوه کنترل فانکشنالیتی آن در تراشههای Virtex-5 به سند UG193 مراجعه کنید.
تراشههای Spartan-3A DSP
معرفی تراشههای Spartan-3A-DSP در سال ۲۰۰۷ آغازی بود بر نسل جدید بلوکهای DSP که تحت عنوان DSP48A Slice نام گذاری شدند.
برخلاف تراشههای Virtex-4 هر XtremeDSP Slice در خانواده تراشههای Spartan-3 DSP تنها متشکل از یک DSP48A Slice بود. علاوه بر پشتیبانی از قابلیتهای معرفی شده در نسلهای قبلی برای اولین مفهوم پیش ضرب کننده یا pre-adder در DSP48A Slice ها معرفی شد. در آن زمان قرارگیری یک جمع/تفریق کننده پیش از عملیات ضرب، یک بروزرسانی چشمگیر محسوب میشد و باعث کاهش قابل توجه منابع منطقی اضافی میشد، از این رو امکان پیاده سازی بهینه فیلترهای متقارن و ضربهای مختلط مهیا شد.
در نگاه اول هر DSP48A Slice دارای یک جمع کننده ۱۸ بیتی است که در ادامه به یک ضرب کننده مکمل دو ۱۸×۱۸ و سپس یک جمع کننده انبارهای ۴۸ بیتی متصل شده است. مشابه نسلهای قبلی رجیسترهای پاپلاین تقریباً در تمامی مسیرهای میانی گنجانده شده است که باعث بهبود چشمگیر کارایی میشوند. معماری داخلی این DSP48A Slice ها در شکل زیر نشان داده شده است.
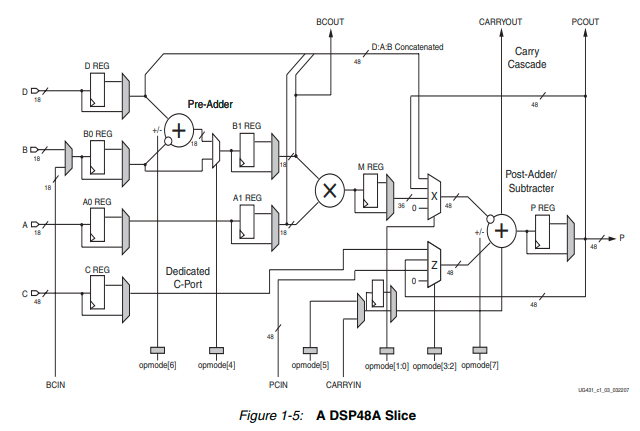
در آخر به این نکته دقت داشته باشید که با توجه به اقتصادی بودن و ارزان قیمت بودن خانوادههای Spartan در مقایسه با خانوادههای Virtex بلوکهای DSP48A در مقایسه با بلوکهای DSP48E تنوع محاسباتی و انعطاف پذیری کمتری داشتند و دیگر از مالتی پلکسر Y در این بلوکها خبری نبود که این مسأله در دیاگرام ساده شده شکل زیر نیز به وضوح نشان داده شده است. برای اطلاعات بیشتر در رابطه با ساختار XtremeDSP DSP48A ها در تراشههای Spartan-3 DSP به سند UG431 مراجعه کنید.
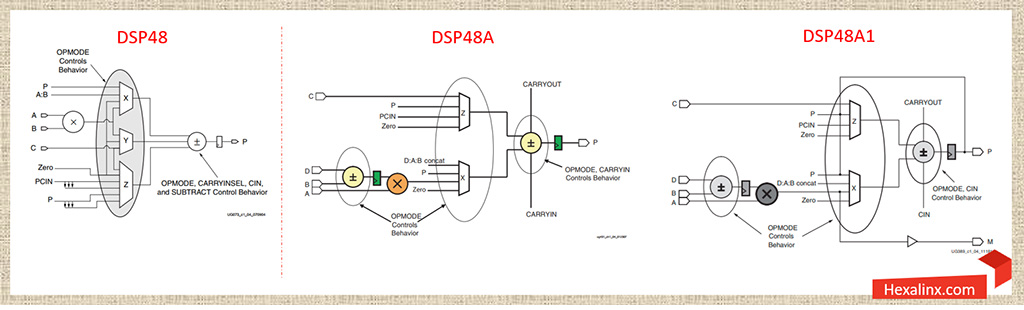
رابطه توصیف کننده خروجی جمع کننده انباره در آخرین طبقه DSP48A Slice به صورت زیر است و مشابهاً با کنترل مناسب مالتی پلکسرهای پیکره بندی، طراح میتواند فانکشنالیتی مد نظرش را فعال کند.
Adder Out = (Z ± (X + CARRYIN))
تراشههای Spartan-6
با معرفی تراشههای Spartan-6 تغییر محسوسی روی معماری بلوکهای پردازش سیگنال اعمال نشد. در واقع DSP48A1 Slice ها در این تراشهها یک بروزرسانی کاملاً کم هزینه در مقایسه با DSP48A Slice های نسل قبلی به حساب میآیند و تغییرات نه چندان قابل ذکری روی آنها اعمال شده است. مهمترین این تغییرات عبارتند از اضافه شدن یک خروجی اختصاصی بعد از عملگر ضرب مرکزی و مدیریت انعطلاف پذیرترِ زنجیره بیت نقلی در مسیرهای آبشاری بین بلوکهای DSP48A1 Slice مجاور که جزئیات آن در شکل زیر نشان داده شده است.
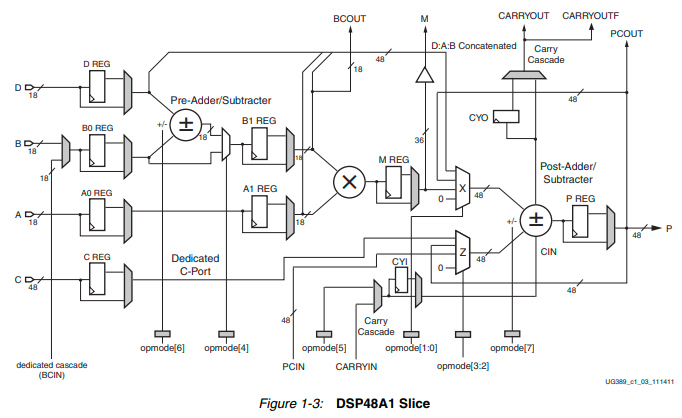
برای اطلاعات بیشتر در رابطه با ساختار DSP48EA1 Slice ها در تراشههای Spartan-6 به سند UG389 مراجعه کنید.
تراشههای Virtex-6
در عمل مهمترین بروزرسانی روی ساختار بلوکهای DSP48 با معرفی نسل سوم آنها در تراشههای Virtex-6 به وقوع پیوست.
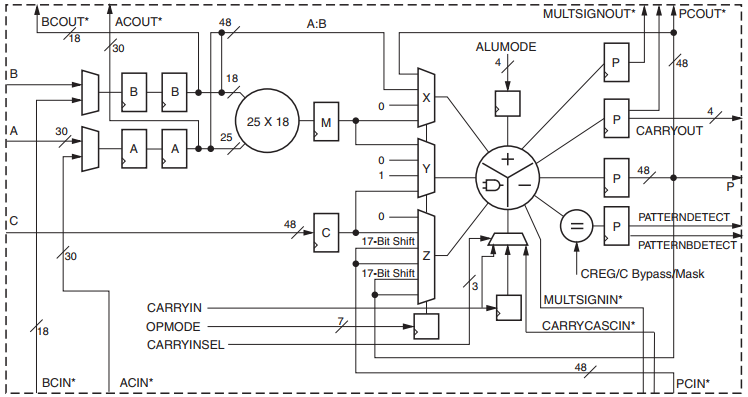
معماری DSP48E1 Slice در تراشههای Virtex-6 کاملا سازگار با معماری DSP48E Slice در تراشههای Virtex-5 است. با اضافه شدن یک پیش جمع کننده ۲۵ بیتی به معماری این بلوکها برای اولین بار تراشههای رده بالای Xilinx مجهز به یک نسخه قدرتمند و تمام عیار از واحدهای سخت افزاری پردازش سیگنال شدند. در نگاه اول این بلوکها متشکل از یک پیش جمع کننده ۲۵ بیتی و یک ضرب کننده مرکزی نسبتاً عریض ۱۸×۲۵ به همراه یک جمع کننده انباره ۴۸ بیتی هستند. جزئیات بخشهای تشکیل دهنده این بلوکها در شکل زیر نشان داده شده است.
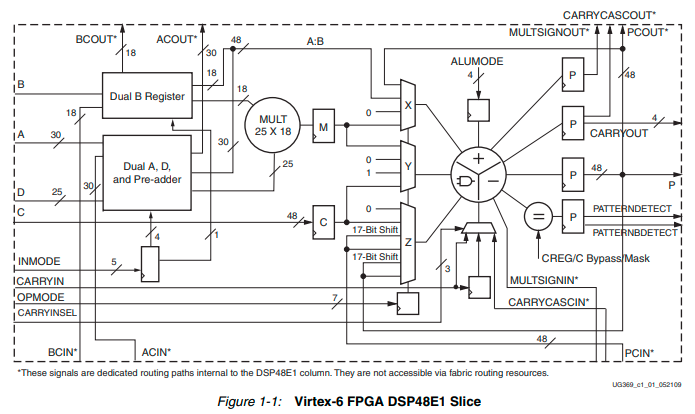
قابلیت اتصال آبشاری بلوکهای DSP که پیش تر نیز وجود داشت در اینجا بازهم تکمیل شده است، واحد ALU در انتهای این بلوکها نیز انعطاف پذیرتر شده است، در کنار تمام این بهینه سازیها امکان کنترل فعال ساز کلاک و ریست تک تک رجیسترهای پایپلاین همچنان وجود دارد.
برای اطلاعات بیشتر در رابطه با ساختار DSP48E1 Slice ها تراشههای Virtex-6 به سند UG369 مراجعه کنید.
تراشههای Series-7
معماری و ساختار بلوکهای DSP48 در کلیه تراشههای سری ۷ کاملاً یکسان است، یعنی بلوکهای DSP48 در تراشه Spartan-7 و Virtex-7 کاملاً با هم سازگار هستند. در واقع Xilinx با یکسان کردن معماری داخلی تراشههای سری ۷ گام بلندی در راستای مقیاس پذیر کردن طراحها هنگام انتقال آنها به تراشههای بزرگتر یا کوچکتر انجام داد.
معماری بلوکهای DSP48 در این تراشهها کاملاً با ساختار این بلوکها در تراشههای Virtex-6 یکسان است از این رو نسل جدید از نقطه نظر فانکشنالیتی کاملاً با نسخه ارائه شده در Virtex-6 سازگار است و تمامی قابلیتهای نسخه ارائه شده در Virtex-5 را نیز پشتیبانی میکند. یادآوری میکنیم که قابلیتهای آن نسبت به نسخه ارائه شده در Spartan-6 کاملاً در سطح بالاتری قرار میگیرد. برای دستیابی به اطلاعات تکمیلی در رابطه با ساختار DSP48E1 Slice ها تراشههای 7-Series به سند UG497 مراجعه کنید.
و نکته آخر اینکه رابطه توصیف کننده خروجی جمع کننده در DSP48E1 Slice کاملاً مشابه DSP48E1 Slice است و به صورت زیر بیان میشود.
Adder/Sub Out = (Z ± (X + Y + CIN)) or (-Z + (X + Y + CIN) –1)
تراشههای UltraScale
در آخرین نسل از FPGA های Xilinx یعنی خانواده تراشههای UltraSclae بازهم نسخه بهینه شده دیگری از DSP48E1 Slice ها با عنوان DSP48E2 Slice معرفی شد. مهمترین تفاوت آن با نسخههای قبلی مربوط به افزایش طول بیت ضرب کننده مرکزی آن از ۱۸×۲۵ به ۱۸×۲۷ و افزایش طول بیت پیش جمع کننده از ۲۵ بیت به ۲۷ بیت است. بعلاوه اینکه عملکرد پیش جمع کننده با انتخاب ورودیهای جدید از مسیرهای آبشاری ACIN و BCIN منعطف تر شده است. عملکرد جمع کننده انبارهای نیز با معرفی سومین ورودی که با F نام گذاری شده است در مقایسه با نسخه قبلی DSP48E1 که دو ورودی داشت، افزایش یافته است. به این ترتیب امکان اجرای عملیات جمع با چهار ورودی در آخرین طبقه مهیا شده است.
انجام یک عملیات منطقی XOR با عرض ۹۶ بیتی با یک DSP48 Slice و همینطور افزایش عرض بیت تا ۱۹۲ بیت در صورت استفاده از DSP48 Slice های مجاور که در یک ستون قرار دارند، دیگر ویژگی مهم اضافه شده به این نسل است. شکل زیر جزئیات معماری داخلی یک DSP48E2 Slice را نشان میدهد.
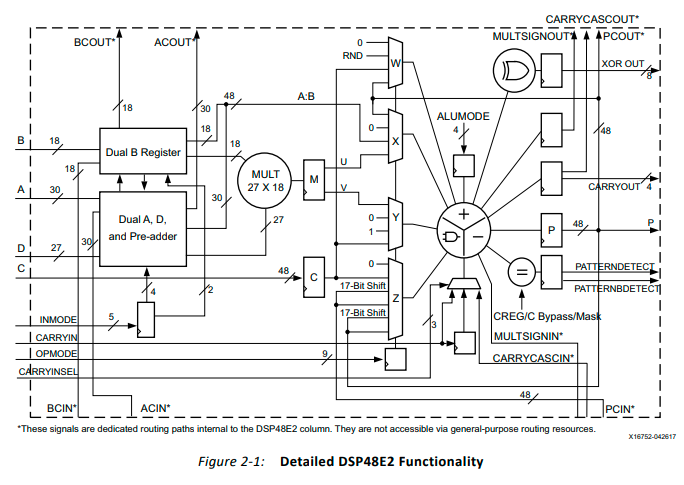
در ساده ترین شکل ممکن میتوان رابطه خروجی جمع کننده در آخرین طبقه DSP48E2 Slice را با توجه به رابطه زیر بیان کرد. برای کسب اطلاعات تکمیلی در رابطه به جزئیات معماری DSP48E2 Slice در تراشههای UltraScale به سند UG579 مراجعه کنید.
Adder/Subtracter Out = (Z ± (W + X + Y + CIN)) or (-Z + (W + X + Y + CIN) –1)
فراخوانی یک بلوک DSP48
فراخوانی مسقیم یک بلوک DSP48 در یک طرح RTL در محیط توسعه ISE و یا Vivado به چند طریق امکان پذیر است که مهمترین آنها عبارتند از:
- استفاده از IP Core ها
- استفاده از Primitive ها و یا Macro های آماده برای هر تراشه
- استفاده از نمونه کدهای آماده Xilinx
نکته: فراخوانی بلوکهای DSP48 در Vivado HLS و System Generator for DSP نیز با استفاده از کتابخانهها یا به اصطلاح IP Library هایی که به صورت پیش فرض در این ابزارها تجمیع شده اند، امکان پذیر است.
استفاده از IP Core ها
در محیط توسعه Vivado در سمت راست از صفحه Flow Navigator گزینه IP Catalog را انتخاب و در فیلد جستجوی آن عبارت DSP48 را تایپ کنید، سپس از لیست IP ها گزینه DSP48 Macro را انتخاب کنید تا پنجره تنظیمات آن برای شما فعال شود.
در محیط توسعه ISE در منوی Project روی گزینه New Source کلیک کنید. از لیست موجود گزینه IP (CORE Generator & Architecture Wizard) را انتخاب کنید. بعد از انتخاب نام مناسب برای IP روی Next کلیک کنید و از لیست IP ها با تایپ عبارت DSP48 گزینه DSP48 Macro را انتخاب کنید. روی Finish کلیک کنید و منتظر بمانید تا پنجره تنظیمات آن برای شما فعال میشود.
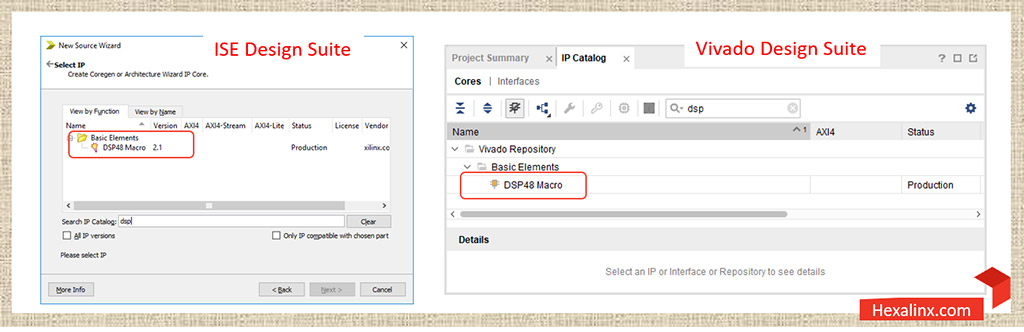
با توجه به خانواده و نوع تراشه انتخابی نسخه DSP48 Macro تنظیمات قابل اعمال در ویزارد سفارشی سازی آن متفاوت خواهد بود، از این رو لازم است قبل از آغاز سفارشی سازی این IP مستندات آن به دقت مطالعه شود.
استفاده از Primitive ها و Macro ها
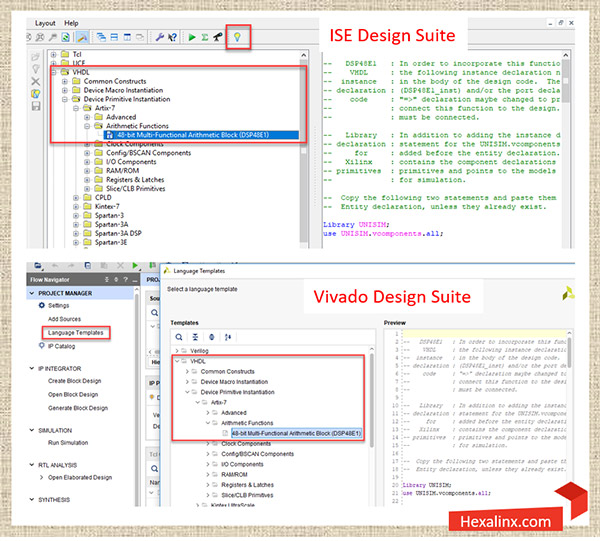
اصطلاح Primitive به واحدهای سخت افزاری درون تراشه FPGA که توسط طراح قابلیت فراخوانی دارند، اطلاق میشود. از آنجا که DSP48 ها واحدهای سخت افزاری هستند پس به شکل Primitive داخل طرح RTL قابل فراخوانی هستند. دسترسی به Primitive ها با استفاده از پنجره Language Template در محیط توسعه Vivado و ISE امکان پذیر است. کافی است از منوی سمت راست در پنجره Language Template به مسیر زیر مراجعه کنید و سپس با انتخاب گزینه 48bit-Arithmetic-Multi-Functional کد مربوط به DSP48 را به طرح RTL اصلی اضافه کنید.
// Primitive
<Language>/Device Primitive Instantiation/<Target Device Family>/Arithmetic Function/48-bit-Multi-Functional Arithmetic
ماکروها (Macros) نمونههای ساده شدهای از Primitive اصلی هستند که کاربر برای استفاده از آنها نیاز به اعمال تنظیمات و مقدار دهی تعداد کمتری سیگنال کنترلی دارند. برای دسترسی به ماکروها از منوی سمت راست در پنجره Language Template به مسیر زیر مراجعه کنید و از بین گزینههای موجود، گزینهای را که به فانکشنالیتی مد نظر شما نزدیکتر است، انتخاب و کد مربوط به آن را به طرح RTL اصلی اضافه کنید.
// Macro
<Language>/Device Macro Instantiation/<Target Device Family>/DSP48/<DSP Macro Example>
در دو مسیر فوق برای Language باید یکی از دو گزینه Verilog و یا VHDL را انتخاب کنید. همینطور برای Target Device Family باید خانواده تراشهای را که قرار است پیاده سازی روی آن انجام شود، انتخاب کنید.
استفاده از نمونه کدهای آماده
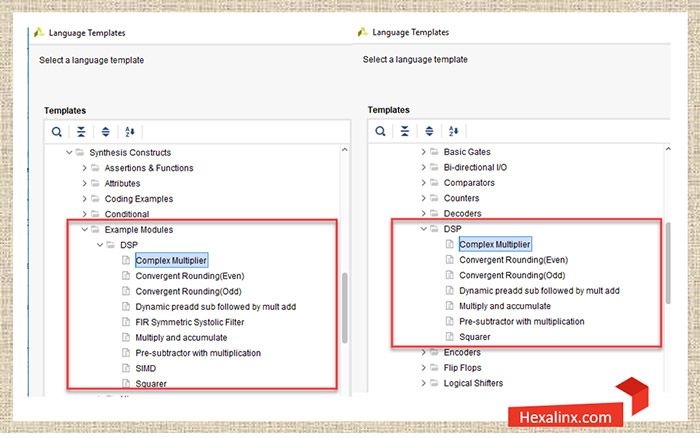
با توجه به توضیحاتی که تا به اینجا ارائه شد، دو روش را برای فراخوانی یک DSP48 Slice در کدهای RTL فرا گرفتید. در هر دو روش این وظیفه طراح است که با استفاده از ویزارد یا مقدار دهی مناسب سیگنالها در کد RTL فانکشنالیتی مد نظرش را پیاده سازی کند، اما در روش سوم این امکان برای طراح وجود دارد که با استفاده از نمونه کدها و مثالهای از پیش آماده که به صورت استاندارد قادر به فراخوانی اتوماتیک DSP48 Macro با یک فانکشنالیتی خاص هستند، استفاده کند. این مثالها قطعه کدهایی هستند که با استفاده از اصول صحیح RTL و مطابق با الزامات ابزار سنتز، کد نویسی شده اند و با استفاده از آنها ابزار سنتز به صورت اتوماتیک DSP48 Macro را با یک فانکشنالیتی خاص فراخوانی و در نت لیست نهایی جایگزین میکند. این قطعه کدها هم برای زبان Verilog و هم برای VHDL وجود دارند و باید با توجه به خانواده تراشه هدف انتخاب شود. برای دسترسی به نمونه کدها و مثالهای آماده مجدداً لازم است از پنجره Language Template کمک بگیرید و به یکی از دو مسیر زیر مراجعه کنید.
// Examples
<Language>/Synthesis Construct/Codding Example/DSP/<DSP Application Example>
<Language>/Synthesis Construct/Example Modules/DSP/<DSP Application Example>
برخی از نمونه کدهای ارائه شده در این بخش به حدی کامل هستند که زمان مورد نیاز شما برای طراحی و کدنویسی یک عملکرد خاص را ساعتها کاهش میدهند. به عنوان مثال همانطور که در تصویر هم مشاهده میکنید شما یک فیلتر FIR و یا SIMD را به کدهای RTL خودتان اضافه کنید.
جمع بندی
تراشههای FPGA به دلیل ظرفیت بالای موازی سازی و انعطاف پذیری که دارند همواره یک انتخاب مناسب برای بکارگیری در اپلیکیشنهای پردازش سیگنال بوده و هستند. اپلیکیشنهای پردازش سیگنال تعداد زیادی ضرب و جمع نیاز دارند که بهترین گزنیه برای پیاده سازی آنها استفاده از DSP48 Slice های اختصاصی درون تراشههای FPGA است. از سال ۲۰۰۴ به بعد تقریباً تمامی تراشههای FPGA از این موهبت بهره مند هستند. بلوکهای DSP48 به شدت قابل سفارشی سازی هستند و فانکشنالیتی آنها با استفاده از تعدادی بیت کنترلی قابل تغییر است. مصرف توان پایین، کارایی بالا، سهولت در استفاده، وجود مسیرهای ارتباطی اختصاصی بین بلوکهای DSP48 مجاور باعث میشود هر طراحی برای استفاده از آنها ثانیه شماری کند.
در انتها یادآور میشویم که فانکشنالیتی قابل حصول توسط این بلوکها فراتر از پردازش سیگنال است و امکان پیاده سازی مدارات تولید کننده آدرس، مدارات شیفت و یا مدارات بازشناسی الگو و … نیز در نسخههای جدیدتر در نظر گرفته شده است.
منبع : UG073 / UG193 / UG431 / UG389 / UG369 / UG497 / UG579






4 دیدگاه برای “بلوکهای DSP48 : قلب تپنده پردازش سیگنال”
سلام.
وقتتون بخیر.
سایتتون واقعا در حوزه FPGA و سایت های فارسی زبان واقعا عالی است.
خیلی عالی تر می شد اگر دوره های بیشتری مثل پیاده سازی الگوریتم های پردازش سیگنال دیجیتال در FPGA و … دوره های Prepare for career یعنی دوره های آماده سازی برای مسیر های مختلف شغلی در حوزه FPGA قرار بدید.
با تشکر
درود فراوان بر شما دوست عزیز، امیدوارم حالتون خوبه خوب باشه
از اظهار لطف صمیمانه شما سپاسگزارم. بدون شک همراهی شما باعث استوار شدن گامهای ما در ادامه این راه میشود.
پیشنهادات شما فوق العاده عالی و کاربردی هستند. فقدان دورههایی که میفرمایید به شدت در کشور احساس میشود. تمام تلاشمان را خواهیم کرد تا در حداقل زمان ممکن موضوعات مد نظر شما و سایر علاقمندان به فعالیت در این حوزه را پوشش دهیم.
واقعا سایت خوبی دارید
بسیار ممنون
سلام بر شما
امیدوارم حالتون عالی باشه. اظهار لطف شما باعث دلگرمی ماست و از فیدبک گرم و صمیمانه شما سپاسگزاریم.