
مقدمه
در این آموزش از پایگاه دانش هگزالینکس برخی از مهمترین تنظیمات و پارامترهای مورد نیاز را برای فرخوانی و بکارگیری Xilinx FFT IP Core در محیط توسعه ISE مرور خواهیم کرد. این مقاله میتواند به عنوان یک نقطه شروع مناسب برای تمام طراحانی که قصد دارند برای اولین بار از Xilinx FFT IP Core برای پیاده سازی تبدیل فوریه در FPGA استفاده کنند، مورد بهره برداری قرار گیرد. در حین این آموزش هر جا که لازم باشد، مطالب تئوریک نیز پوشش داده خواهد شد. با این وجود دقت داشته باشید که هدف این مقاله ارائه توضیحات تئوریک نیست و قصد ما تمرکز روی پیاده سازی FFT است.
تبدیل فوریه سریع یا اصطلاحاً Fast Fourier Transform (FFT) به کلاسی از الگوریتمهای پردازش سیگنال اطلاق میشود که میتوانند به شکل بهینه تبدیل فوریه گسسته یا اصطلاحاً Discrete Fourier Transform (DFT) را برای یک دنباله محاسبه کنند. در واقع DFT یک ابزار قدرتمند برای آنالیز و طراحی سیستمهای پردازش سیگنال دیجیتال است و در نتیجه FFT به شکل گستردهای در بسیاری از اپلیکیشنهای پردازش سیگنال بکار گرفته میشود.
در نگاه اول FFT الگوریتم نسبتاً پیچیدهای است (البته همینطور هم هست) و پیاده سازی بهینه سخت افزاری آن میتواند کاملا چالش برانگیز باشد. به همین دلیل است که اکثر سازندگان تراشههای FPGA یک IP Core قابل سفارشی سازی در اختیار کاربرانشان قرار میدهند. اگر چه با استفاده از این IP Core ها مهندس پیاده ساز به راحتی و تنها با چند کلیک میتواند یک الگوریتم FFT به طرحش اضافه کند، اما با این وجود برای استفاده از آنها بازهم نیاز دارد برخی از جزئیات پیاده سازی FFT روی سخت افزار را بشناسد.
برای اینکه با نحوه استفاده از IP Core ها در محیط توسعه Xilinx ISE آشنا شوید میتوانید مقاله آموزشی محاسبه سینوس و کسینوس در FPGA با استفاده از CORDIC را نیز مطالعه بفرمایید.
اضافه کردن FFT IP Core
پیاده سازی FFT با استفاده از نسخه 14.7 مجموعه نرم افزاری ISE صورت پذیرفته است. با فرض اینکه شما آشنایی کافی با شیوه ساخت پروژه در ISE Project Navigator دارید، مستقیمأ به سراغ فراخوانی Xilinx FFT IP Core میرویم. برای اضافه کردن IP Core به پروژه ISE به صورت زیر عمل کنید.
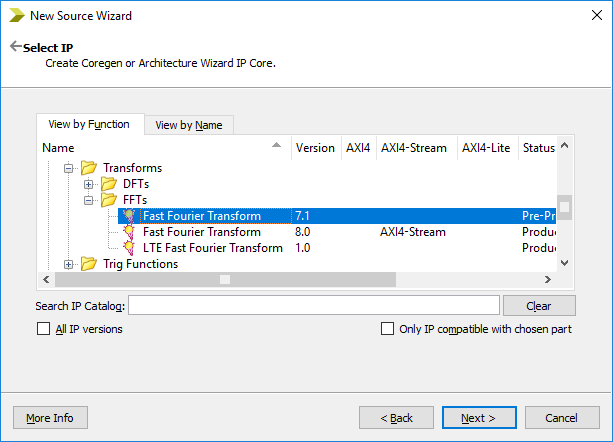
۱- در تب Project روی گزینه New Source کلیک کنید و از لیست موجود گزینه “IP (CORE Generator & Architecture Wizard)” را مطابق با آنچه در شکل زیر نشان داده شده است، انتخاب کنید.
۲- برای فایل خود یک نام انتخاب کنید و آدرس مورد نظر برای ذخیره سازی را تعیین کنید و روی Next کلیک کنید. در صفحه بعدی ویزارد لیست تمامی IP Core های موجود و قابل فراخوانی در ISE را خواهید دید.
۳- از لیست موجود با تایپ عبارت Fast Fourier Transform در فیلد Search IP Catalog گزینه Fast Fourier Transform 7.1 را انتخاب کنید. این IP با جستجوی مستقیم در زیر بخش Digital Signal Processing\Transforms\FFTs نیز قابل دسترسی است. البته نسخه 8.0 آن نیز با استفاده از اینترفیس AXI-Stream در دسترس است که در این مقاله به آن نمیپردازیم.
تنظیم پارامترها
ویزارد تنظیمات این IP متشکل از سه صفحه است که تنظیمات موجود در اولین صفحه آن نیز در سه بخش دسته بندی شده است. در سمت چپ این صفحه میتوانید شماتیک و ورودی/خروجیهای فعال آن را در تب IP Symbol مشاهده کنید. این ورودی/خروجیها با توجه به انتخابهای شما تغییر خواهند کرد. همینطور منابع مصرفی مورد نیاز برای پیاده سازی معماریهای مختلف در تب Resources قابل مشاهده است. دو تب دیگر به نام Latency و C model نیز در سمت چپ وجود دارد که در ادامه معرفی میشوند.
با کلیک روی کلید Datasheet در پایین صفحه شما میتوانید به سند راهنمای کاربری این IP در سایت Xilinx دسترسی پیدا کنید. در این سند کلیه جزئیات در رابطه با شیوه سفارشی سازی و استفاده از Xilinx FFT IP Core توضیح داده شده است. همینطور به شکل خلاصه تئوری کاری الگوریتم نیز در آن گنجانده شده است. در ادامه ما مهمترین ویژگیها و مشخصههای این IP را تشریح خواهیم کرد.

در بالای صفحه در بخش Channels ، شما میتوانید تعداد کانالهای این IP Core را تعیین کنید. این گزینه زمانهایی که شما نیاز به محاسبه یک FFT روی چندین سیگنال متفاوت دارید، کاربرد دارد. اگر تمام این FFT ها پارامترهای یکسانی داشته باشند، در این صورت شما میتوانید به جای فراخوانی چندین بلوک FFT تک کاناله در کدهای HDL از یک بلوک FFT چندکاناله استفاده کنید. این شکل از پیاده سازی منجربه به کاهش منابع مصرفی روی تراشه میشود، چون ابزار سنتز به صورت اتوماتیک با به اشتراک گذاری منابع، برخی از مدارات کنترلی تکراری را حذف میکند و در نهایت شما پیاده سازی بهینه تری خواهید داشت.
در ISE به شما امکان پیاده سازی FFT با ۱۲ کانال داده شده است. اگر ساختار چند کاناله برای پیاده سازی انتخاب شود، تعداد برخی از پورتها، همچون پورتهای داده ورودی و خروجی چند برابر میشوند، تا امکان کار روی چندین سیگنال یا دنباله ورودی به صورت هم زمان امکان پذیر گردد. این مسأله در سمت چپ ویزارد تنظیمات و در تب IP Symbol به سادگی قابل بررسی است. نکتهای که باید به آن توجه شود این است که در صورت استفاده از ساختار Pipelined, Streaming I/O در بخش Implementation Options دیگر قادر به استفاده از کارکرد چندکاناله (multi-channel) نخواهید بود و همانطور که مشاهده میکنید، این قابلیت پشتیبانی نمیشود.
بخش Transform Length به شما اجازه میدهد طول دنباله یا پنجرهای را که تبدیل فوریه روی آن محاسبه میشود، تعیین کنید. در ISE حداکثر طول مجاز پیاده سازی دنبالهای با ۶۵۵۳۶ نمونه است.
بخش Implementation Options جزئیات نسبتاً مهم تری دارد و قصد داریم وقت بیشتری را به توضیح آن اختصاص بدهیم.
انتخاب معماری پیاده سازی FFT
همانطور که در صفحه اول تنظیمات مشاهده میکنید، پنج انتخاب متفاوت برای پیاده سازی FFT وجود دارد. اولین انتخاب گزینه Automatically Select است. در صورت انتخاب آن ابزار به صورت اتوماتیک کوچکترین پیاده سازی (به لحاظ منابع مصرفی) را برای برآورده شدن ظرفیت خروجی مورد انتظار (پارامتر Target Data Throughput) در مقابل فرکانس کلاک قابل تأمین (پارامتر Target Clock Frequency) فراخوانی میکند.
نکته مهمی که در اینجا باید به آن توجه کرد این است که دو پارامتر Target Data Throughput و Target Clock Frequency تنها برای انتخاب معماری پیاده سازی و محاسبه تأخیر نهایی طرح استفاده میشوند. شما میتوانید از هر کلاکی و با هر فرکانسی برای ارسال داده به IP Core استفاده کنید و مطمئن باشید خللی در عملکرد آن ایجاد نمیشود. با این وجود در صورتی که فرکانس واقعی کلاک با مقادیری که در اینجا تنظیم میشود متفاوت باشد، تأخیر طرح نهایی شما با گزارشهای خروجی ویزارد تنظیمات که در تب Latency ارائه میشود، متفاوت خواهد بود، این مسأله در انجمنهای گفتگوی Xilinx به صراحت بیان شده است.
حق انتخابهای شما برای پیاده سازی با توجه گزینههای موجود در صفحه اول ویزارد به شرح زیر است:
Pipelined, Streaming I/O Radix-4, Burst I/O Radix-2, Burst I/O Radix-2 Lite, Burst I/O
معماریهای متفاوت امکان برقراری یک مصالحه بین منابع مصرفی و تأخیر طرح را به شما میدهند. این مصالحه در شکل ۳ قابل مشاهده است. قاعده کی به این صورت است که سایز IP پیاده سازی شده با فاکتور ۲ در هر معماری نسبت به معماری دیگر تغییر میکند.
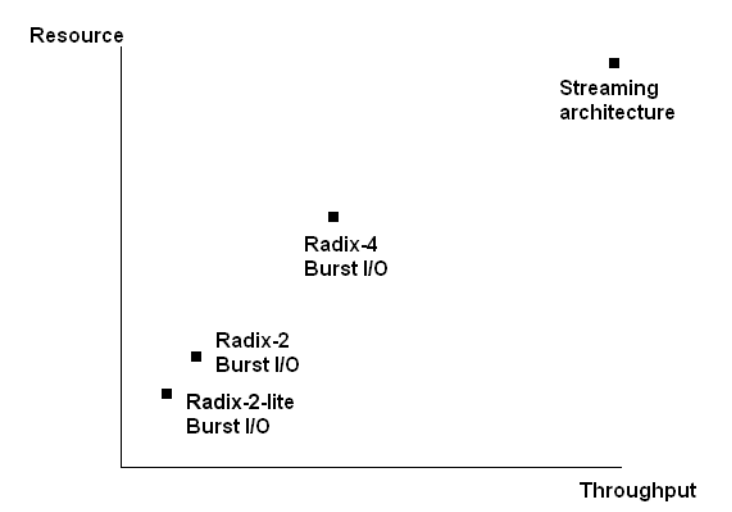
معماری Pipelined, Streaming I/O پردازش فریمهای دیتا را به صورت پشت سرهم و بی وقفه امکان پذیر میکند. با این پیاده سازی امکان پردازش هم زمان فریم های دیتای جدید و خروجی کردن دادههای پرداش شده فریمهای قبلی مهیا میگردد. در عین حال با استفاده از معماریهای Radix-4, Burst I/O و Radix-2, Burst I/O و Radix-2 Lite, Burst I/O امکان پردازش استریم دیتا وجود نخواهد داشت و استفاده از خروجیها هم زمان با لود ورودیهای جدید امکان پذیر نخواهد بود.
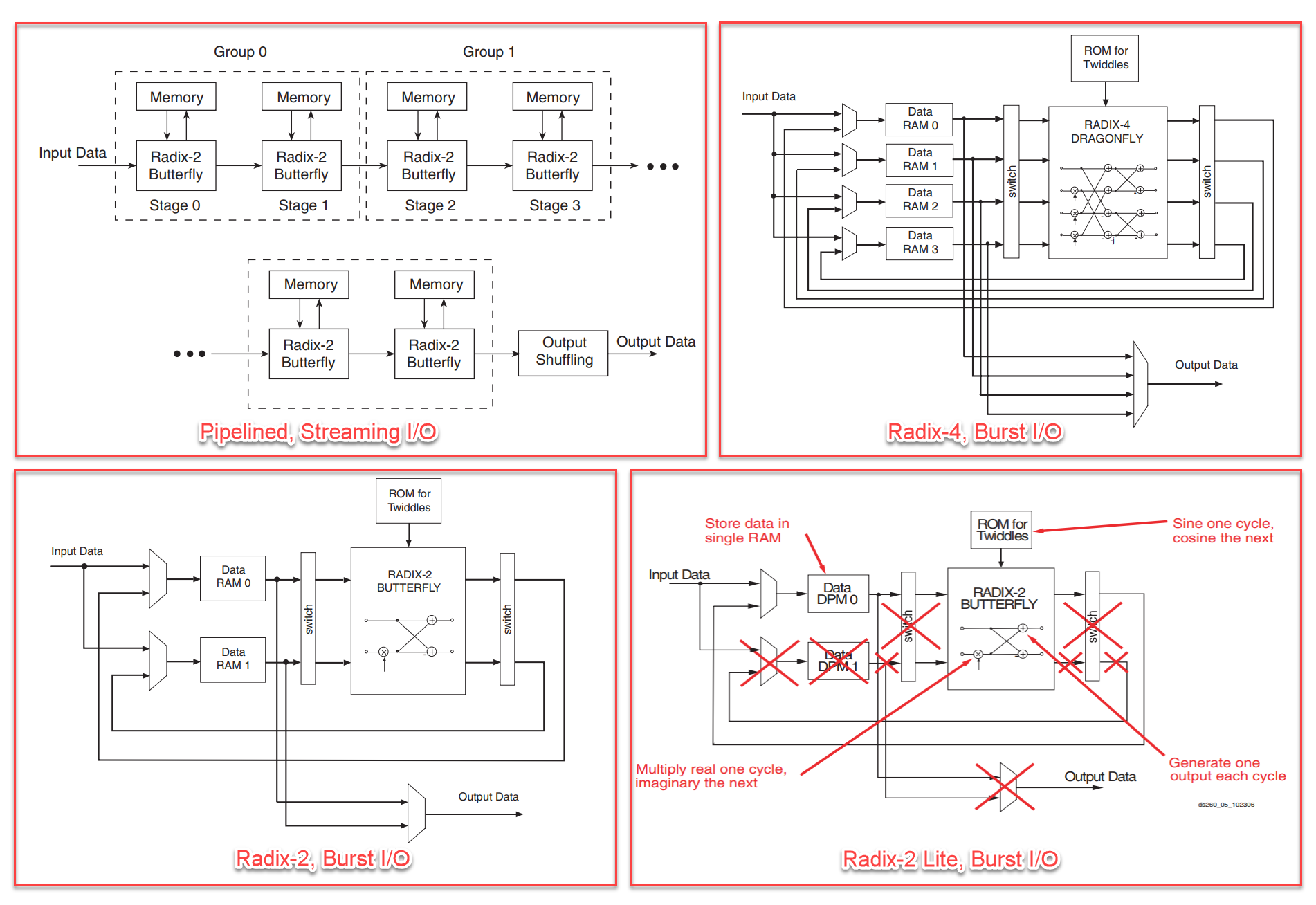
برای پیاده سازی FFT با معماری Pipelined, Streaming I/O ، ما ابتدا نیاز داریم یک فریم دیتا لود کنیم، تبدیل فوریه را محاسبه کنیم، و سپس داده خروجی را مصرف کنیم. مصرف نتایج فریم فعلی میتواند همزمان با لود فریم دیتای جدید انجام شود، البته برای اینکه موفق به این کار شویم باید علاوه بر انتخاب صحیح معماری، تنظیمات مربوط به بخش bit/digit-reversed order نیز به درستی اعمال شود. در ادامه در این رابطه بیشتر صحبت خواهیم کرد.
آخرین بخش از اولین صفحه ویزارد تنظیمات Transform Length Options است که در آن یک گزینه به نام Run Time Configurable Transform Length وجود دارد. انتخاب کردن این گزینه امکان باز پیکره بندی طول FFT را در زمان اجرا فراهم میآورد. در صورت انتخاب این گزینه دو پورت جدید به نامهای NFFT و NFFT_WE به بلوک دیاگرام IP در تب IP Symbol اضافه میشود. پورت ورودی NFFT برای تعیین طول فریم یا طول تبدیل در زمان اجرا استفاده میشود و پورت NFFT_WE که یک پورت فعال ساز است و لحظهای را که مقدار NFFT روی پورت معتبر است، مشخص میکند. در طول زمان اجرا میتوان هر عددی که کوچکتر از، یا برابر با مقدار تعیین شده در بخش Transform Length باشد، به پورت NFFT نسبت داد. به عنوان مثال یک بلوک FFT با طول فریم ۱۰۲۴ نقطه میتواند تبدیل فوریه سریع را برای تمام فریمهای با طول کوچکتر یا مساوی ۱۰۲۴ یعنی ۱۰۲۴ و ۵۱۲ و ۲۵۶ نقطه و … محاسبه کند. انتخاب این گزینه هم منجربه افزایش سایز منابع مصرفی و همینطور کاهش حداکثر فرکانس کاری Xilinx FFT IP Core میشود.
با کلیک روی Next در پایین صفحه ویزارد به صفحه دوم تنظمیات ویزارد بروید.
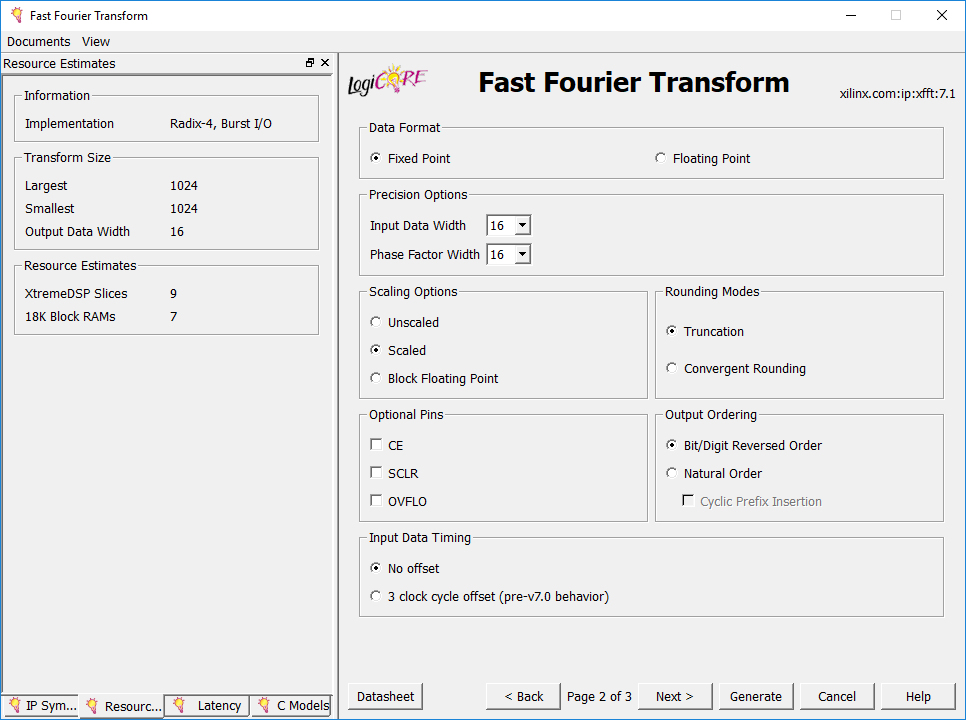
بخش Data Format، به شما اجازه میدهد که فرمت دیتای ورودی و خروجی را تعیین کنید. انتخابهای شما در اینجا باید یکی از گزینههای ممیز ثابت (Fixed Point) و یا ممیز شناور (Floating Point) باشد. البته در صورتی که مُد عملکردی چند کاناله برای IP Core انتخاب شده باشد گزینه Floating Point غیر فعال خواهد بود.
بخش Precision Options برای تعیین تعداد بیتهای مورد استفاده برای نمونههای ورودی و ضرایب استفاده میشود. عبارت Phase Factor اشاره به ضرایب ثابت مثلثاتی دارد که برای ضرب در نمونههای ورودی استفاده میشوند. همانطور که ملاحظه میکنید تعداد بیتها و در نتیجه دقت آنها به صورت مستقل از هم با گزینه Input Data Width و Phase Factor Width قابل تعیین است.
تنظیمات بعدی به بخش Scaling Options تعلق دارد. این بخش مربوط به نحوه کنترل رشد بیت ناشی از محاسباتی است که در روند اجرای الگوریتم ایجاد میشود. برای اینکه دید بهتری نسبت به این موضوع بدست بیاورید، سیگنال فلوگراف الگوریتم radix-2 decimation FFT هشت نقطهای را مشابه چیزی که در شکل ۶ نشان داده شده است، در نظر بگیرید.
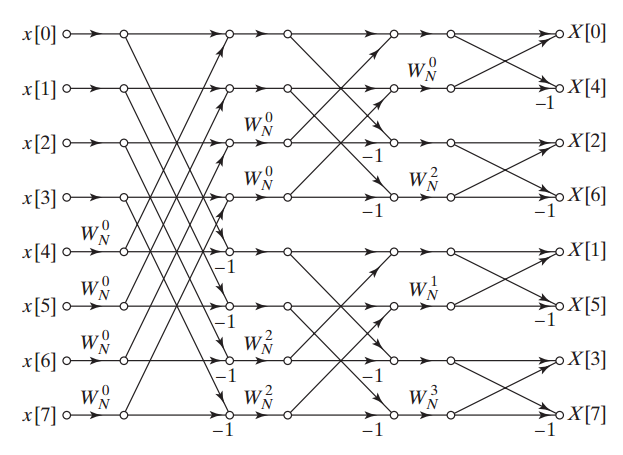
اگر با این سیگنال فلوگراف آشنا نیستید، حتماً به شکل اجمالی در کتابهای پردازش سیگنال در رابطه با آن مطالعه کنید. ما میتوانیم این سیگنال فلوگراف را به واحدهای کوچکی به نام باترفلای (Butterfly) به صورت شکل ۷ تجزیه کنیم. این نام گذاری با توجه به شکل آنها که شبیه پروانه است، انجام شده است. در ادامه این مقاله برای سادگی نگارش ما از عنوان باترفلای برای مخاطب قرار دادن این واحدهای کوچک محاسباتی استفاده خواهیم کرد.
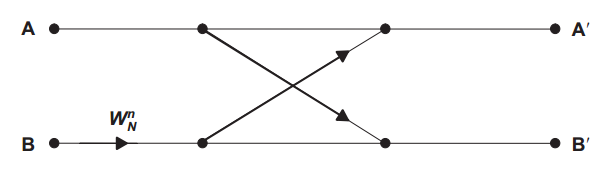
در بخشهای مختلف سیگنال فلوگراف شکل ۶ از این باترفلای با ضرایب یا وزنهای (Phase Factors) مختلف که با نماد WNn قابل مشاهده است، استفاده شده است. مقادیر ’A و ’B با استفاده از روابط زیر محاسبه میشوند.
$$A^{‘} = A + W_{N}^{n} B$$
$$B^{‘} = A – W_{N}^{n} B$$
تمامی متغیرها در روابط بالا مقادیر مختلط هستند از این رو واضح است که برای محاسبه دو حاصلضرب مختلط فوق نیاز به محاسبه چهار حاصلضرب حقیقی داریم. به سادگی میتوان نشان داد که هر کدام از بخشهای حقیقی و یا موهومی ’A و ’B با فاکتور 2.414 ~ sqrt(2) + 1 با مقادیر حقیقی و موهومی A و B یعنی سیگنالهای ورودی باترفلای در ارتباط هستند. با درنظر گرفتن فاکتور 2.414 برای یک باترفلای در مبنای ۲ (شکل ۷)، ما نیاز به افزایش طول بیت رجیسترهای ذخیره کننده ’A و ’B با دو بیت بیشتر نسبت به طول بیت رجیسترهای A و B خواهیم داشت، در غیر این صورت سرریز اتفاق میافتد و درستی محاسبات زیر سوأل میرود.
کنترل رشد بیت
در بخش Scaling Options از دومین صفحه تنظیمات ویزارد، رویکرد متفاوتی برای کنترل رشد طول بیت و غلبه بر مشکل سرریز مورد استفاده قرار گرفته است. در ادامه گزینههایی که در این بخش در اختیار شما قرار میگیرد، بررسی خواهیم کرد.
مقیاس بندی نشده (Unscaled)
با انتخاب گزینه مقیاس بندی نشده (Unscaled)، طول بیت رجیسترها به اندازه کافی بزرگ انتخاب میشود تا از وقوع هرگونه سرریز جلوگیری شود. این ملاحظه باعث افزایش قابل توجه منابع مصرفی روی تراشه میشود. همانطور که اشاره شد خروجی یک باترفلای در مبنای ۲ حداکثر ممکن است دو بیت نسبت به ورودی آن رشد بیت داشته باشد. اما این لزوماً بدان معنا نیست که خروجی تمامی باترفلایها دو بیت رشد دارند. در حقیقت برای اینکه محاسبات مقیاس بندی نشده با دقت کامل و بدون سرریز انجام شوند IP Core به صورت اتوماتیک بخش صحیح خروجی FFT را با توجه به رابطه زیر محاسبه میکند.
integer width of the input+log2(transform length)+1
به عنوان مثال، فرض کنید که شما یک FFT مقیاس بندی نشده و ۱۰۲۴ نقطهای دارید که ورودیهای آن ۱۶ بیتی هستند و ۳ بیت برای بخش صحیح و ۱۳ بیت برای بخش اعشاری آن در نظر گرفته شده است. با توجه به رابطه بالا انتظار داریم طول بیت خروجی ۱۴=۱+۱۰+۳ باشد. از آنجایی که ابزار سنتز همواره طول بیت بخش اعشاری خروجی را برابر با بخش اعشاری ورودی در نظر میگیرد. بنابراین طول بیت نهایی خروجی FFT برابر با ۲۷=۱۴+۱۳ بیت خواهد بود. دقت کنید که طول بیت بخش صحیح با هدف جلوگیری از بروز سرریز انتخاب شده است در حالیکه طول بیت بخش اعشاری براساس خطای کوانتیزاسیون قابل پذیرش انتخاب شده است.
مقیاس بندی شده (Scaled)
در صورتی که گزینه مقیاس بندی شده (Scaled) انتخاب شود، طراح میتواند از یک مکانیزم خاص و قابل سفارشی سازی، برای کنترل رشد بیت خروجی استفاده کند. این کار اصطلاحاً تحت عنوان برنامه مقیاس بندی یا scaling schedule شناخته میشود. با انتخاب این گزینه، نتایج محاسبات طبقات مختلف الگوریتم (خروجی باترفلایها) با توجه به مقدار پارامتر scaling که توسط طراح تعیین میشود، به سمت راست شیفت داده خواهند شد (شیفت به راست معادل عملیات تقسیم است) و به این ترتیب از وقوع سرریز جلوگیری می شود.
برای مثال، فرض کنید که یک FFT با طول ۱۰۲۴ نقطه و با معماری Radix-2, Burst I/O پیاده سازی کردهاید. در نتیجه برای این FFT شما log2(1024)=10 طبقه در مبنای ۲ خواهید داشت. بنابر این با توجه به اطلاعات مندرج در دیتا شیت IP Core شما به ۱۰ مقدار مقیاس بندی (scaling) نیاز خواهید داشت. برای این مثال خاص میتوان از دنباله [01 01 01 01 01 01 01 01 01 10] که یک برنامه محافظه کارانه مقیاس بندی (conservative scaling schedule) است به عنوان مقادیر مقیاس بندی استفاده کرد. این دنباله عددی به این ترتیب خوانده میشود.
- شیفت به راست به اندازه دو بیت برای طبقه صفرم
- شیفت به راست به اندازه یک بیت برای طبقات دوم تا نهم
به عبارت دیگر، دو بیت کم ارزش معرف مقدار مقیاس بندی برای دو طبقه صفرم، دو بیت بعدی معرف مقدار مقیاس بندی برای طبقه یکم و به همین ترتیب الی آخر است. این مقادیر مقیاس بندی از طریق پورت خاصی که برای این منظور به IP اضافه میشود، به آن اعمال میشود. این پورت SCALE_SCH نام دارد. نکتهای که باید به آن توجه شود این است که تعیین مقادیر بهینه برای طبقات مختلف الگوریتمFFT با هدف جلوگیری از وقوع سرریز کاری بسیار دشوار است. یکی از دلایلی که Xilinx برای این IP Core یک مدل اختصاصی به زبان C یا اصطلاحاً (C model) ارائه کرده است، همین موضوع است. شما به عنوان طراح میتوانید از این C model برای بدست آوردن کوچکترین مقادیر ممکن مقیاس بندی با توجه به ماهیت سیگنال ورودی به FFT استفاده کنید. البته این C model کاربردهای دیگری هم دارد که توضیح آن خارج از حوصله این مقاله است و به تفصیل در دیتاشیت IP توضیح داده شده است.
ممیز شناور (Block Floating Point)
گزینه Block Floating Point سومین انتخاب برای جلوگیری از مشکل سرریز است. وقتی که سیگنال ورودی FFT به خوبی قابل آنالیز و پیش بینی نباشد و یا رنج دینامیکی تغییرات نمونههای ورودی کاملاً بزرگ باشد، در این صورت استفاده از مد Scaled امکان پذیر نیست. در چنین شرایطی میتوان از مد Block Floating Point استفاده کرد. این انتخاب به IP Core اجازه میدهد که با هدف جلوگیری از بروز سرریز بهترین مقادیر را برای مقیاس بندی طبقات مختلف الگوریتم، تعیین کند. مقدار برنامه مقیاس بندی بعد از هر بار اجرای الگوریتم FFT با استفاده از یک پورت جدید به نام BLK_EXP خروجی میشود. البته لازم به ذکر است که مد Block Floating Point ممکن است نیاز به منابع سخت افزاری قابل توجهی در مقایسه با مد Scaled داشته باشد.
صحبت در مورد نحوه کنترل رشد بیت تا همین جا کافیست، کار را با بررسی تنظیمات باقی مانده ادامه میدهیم.
بخش Rounding Modes به منظور انتخاب تکنیکهای کنترل رشد بیت برای کاهش طول بیت بخش اعشاری محاسبات باترفلای مورد استفاده قرار میگیرد. در این بخش دو گزینه برای انتخاب وجود دارد که اولی روش Truncation و دومی روش Convergent Rounding است. روش ترانکیشن (Truncation) نسبتاً آسان و سر راست است و به سخت افزار کمی نیاز دارد. در نقطه مقابل روش گرد کردن (Convergent Rounding) روش دقیق تری است و از شکل گیری بایاس DC روی مقادیر خروجی جلوگیری میکند.
بخش Optional Pins به شما امکان افزودن چندین پین اضافی را به IP Core میدهد. پینهایی همچون فعال ساز کلاک (CE) و یا ریست سنکرون (SCLR) که به صورت سنکرون و طی چندین سیکل کلاک بافرهای داخلی را پاک میکند.
در بخش Output Ordering شما میتوانید ترتیب نمونهها را هنگام خروج از IP Core مشخص کنید. گزینههای قابل انتخاب در این بخش Natural Order و Bit/Digit Reversed Order است.
تنظیمات Bit/Digit-Reversed Order چیست؟
از نقطه نظر پیاده سازی، ساده ترین راه برای تولید خروجیهای الگوریتم FFT ترتیبی است که اصطلاحاً Bit/Digit-Reversed Order نامیده میشود.
به عنوان مثال، یک بلوک ۸ نقطهای FFT با معماری radix-2 که به صورت پشت سرهم دادهها را دریافت میکند، ابتدا ۸ نمونه دیتا در حوزه زمان دریافت میکند و بعد به صورت پشت سرهم دادههای خروجی FFT را تولید میکند. در حالت کلی شما میتوانید نمونههای ورودی را کاملاً مرتب به ورودی FFT اعمال کنید، یعنی ابتدا نمونه ورودی x[0] و سپس نمونه x[1] و بعد از آن نمونه x[2] و به همین ترتیب الی آخر. در حالی که الگوریتم FFT و همینطور Xilinx FFT IP Core به شکلی طراحی شدهاند که نمونههای خروجی را با یک الگوی خاص و به ترتیب x[0] و بعد x[4] و x[2] و x[6] و x[1] و x[5] و x[3] و در نهایت x[7] خروجی میکنند. اگر نگاهی تیز بینانه به اندیسِ نمونههای خروجی در فرمت باینری داشته باشید، مشاهده خواهید کرد اندیسها به صورت “000” و “100”و بعد “010” و “110”و به همین شکل الی آخر هستند. به نظر میرسد اگر یک آینه در مقابل اندیسها قرار دهیم، توالی شمارهها کاملاً مرتب میشوند و اندیسها برابر با “000” و “001” و “010” میشوند. در عمل اندیسهای خروجی نسخه آینه شده یا mirrored یا اصطلاحاً bit-reversed اندیسهای ورودی هستند.
به همین دلیل است که گفته میشود ترتیب ظاهر شدن نمونهها در خروجی الگوریتم به صورت bit-reversed است. مثال فوق در رابطه با معماریهای radix-2 بود. برای اینکه مثالی از اندیسهای digit-reversed در معماری radix-4 ببینید، میتوانید به دیتاشیت Xilinx FFT IP Core مراجعه کنید.
تولید نمونههای خروجی FFT با ترتیب پیش فرض bit/digit reversed نه تنها باعث استفاده بهینه از منابع حافظه میشود بلکه تا حدود زیادی کار طراحی و پیاده سازی را ساده تر میکند. با این وجود مرتب کردن توالی دادهها (Natural Order) در خروجی مزایایی به همراه دارد که نمیتوان از آنها چشم پوشی کرد. به همین دلیل است که معمولاً مزایای حاصل از خروجیهای bit-reversed کنار گذاشته میشود و یکسری مدارات اضافی برای از بین بردن اثر آن در خروجی FFT قرار میگیرند. اما در حالت استاندارد اگر ساده بودن طرح و مینیمم کردن منابع مصرفی همچنان اولویت داشته باشد، میتوان با توجه به متقارن بودن ساختار FFT به جای ورودیهای مرتب از ورودیهای bit-reserved استفاده کرد. در این صورت انتظار داریم نمونههای خروجیهای FFT کاملاً مرتب روی پورتهای خروجی قرار بگیرند. البته Xilinx FFT IP Core از این قابلیت پشتیبانی نمیکند.
نمونههای خروجی Xilinx FFT IP Core میتوانند Bit/Digit-reversed و یا Natural باشند. در صورتی که مُد Natural Order انتخاب شود ممکن است با توجه به معماری انتخاب شده برای پیاده سازی یکی از دو اتفاق زیر بیافتد.
- افزایش مصرف منابع حافظه تراشه
- افزایش تأخیر و در نتیجه کاهش ظرفیت خروجی
بخش Input Data Timing با هدف ایجاد سازگاری بین نسخههای مختلف IP Core استفاده میشود. در نسخههای قبلی IP Core یک تأخیر زمانی بین اندیسِ نمونهها و خود نمونههای ورودی به آن وجود داشت که در نسخههای جدیدتر حذف شده است. به طور کلی شما برای تمام طراحیهای جدید میتوانید بدون دغدغه گزینه No Offset را انتخاب کنید.
در ادامه با کلیک روی Next به صفحه سوم ویزارد تنظیمات منتقل میشوید، در آخرین صفحه ویزارد برخی از تنظیمات پیاده سازی را مشاهده خواهید کرد. با استفاده از انتخابهایی که در این صفحه وجود دارد شما قادر خواهید بود با توجه به نیازمندی و الزامات پروژه کنترل نسبی روی ترکیب منابع مصرفی اعمال کنید. گزینهها در این صفحه چندان پیچیده نیستند و مرور آنها به زمان زیادی نیاز ندارد از این رو به شکل خلاصه و تیتر وار آنها را بررسی میکنیم.
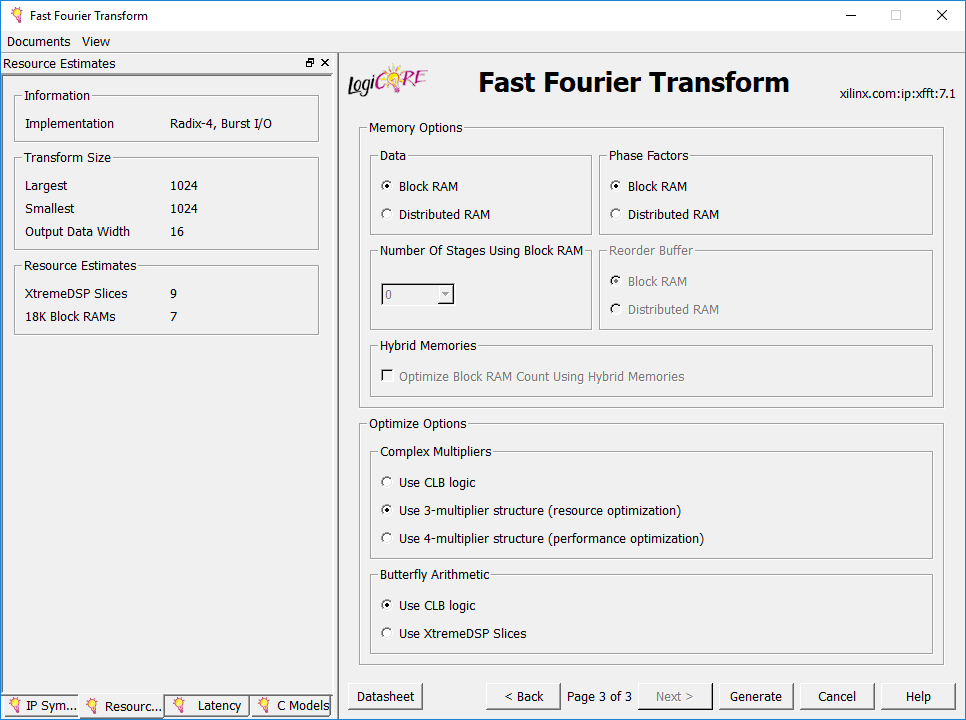
بخش Memory Options، به شما اجازه میدهد نوع منابع حافظه موجود برای پیاده سازی را انتخاب کنید. گزینههای شما در اینجا حافظههای بلوکی (Block RAM) و حافظههای توزیع شده (Distributed RAM) است. تنظیمات حافظه برای هر یک از متغیرهای شرکت کننده در محاسبات میتواند به صورت مستقل انجام شود.
اگر معماری Pipelined, Streaming I/O برای پیاده سازی انتخاب شده باشد، در این صورت امکان استفاده ترکیبی از حافظههای بلوکی و حافظههای توزیع شده برای ذخیره نتایج هر طبقه وجود خواهد داشت. به طور کلی هر چقدر از سمت ورودی به سمت خروجی در فلوگراف FFT حرکت کنید، حافظه مورد نیاز برای ذخیره ضرایب (Phase Factors) کاهش مییابد. شما به عنوان طراح میتوانید تعداد طبقات پایپلانی را که تمایل دارید با استفاده از حافظهای بلوکی پیاده سازی شوند با وارد کردن یک عدد در فیلد Number Of Stages Using Block RAM مشخص کنید. همینطور در صورتی که گزینه Natural Order در صفحه قبل فعال شده باشد، نوع حافظه مورد استفاده برای بافر خروجی هم قابل انتخاب است.
امکان جالب دیگری که در اختیار شما قرار دارد مربوط به گزینه Hybrid Memory است. در صورت فعال بودن این گزینه اگر اندازه حافظه مورد نیاز در هر طبقه پایپلاین الگوریتم بزرگتر از اندازه استاندارد یک یا چند حافظه بلوکی باشد (مضرب صحیحی نباشد)، آنگاه بخش اعظم حافظه در Block RAM ها و مابقی آن در Distributed RAM ها ذخیره میشود. این کار باعث صرفه جویی در منابع حافظه مصرفی میشود.
بخش Optimize Options، به تعیین ساختار ضرب کننده مختلطی که در فلوگراف FFT مورد نیاز است، اختصاص دارد. ساختار انتخابی برای پیاده سازی ضرب کنندهها میتواند یکی از سه گزینه زیر باشد.
- گزینه اول Use CLB logic است. یعنی تمام ضربها با استفاده از منابع منطقی تراشه در CLBها انحام شود.
- گزینه دوم Use 3-multiplier structure است. یعنی برای محاسبه ضرب مختلط از ساختار خاصی که با سه بلوک DSP48 پیاده سازی میشود، استفاده شود. انتخاب این گزینه افزایش تأخیر محاسبات و کاهش منایع مصرفی را به همراه دارد.
- گزینه سوم Use 4-multiplier structure است. یعنی بدون اعمال هیچ گونه ملاحظه خاصی هر ضرب مختلط با چهار ضرب حقیقی پیاده سازی شود.
در آخرین گام منابع سخت افزاری مورد نیاز برای Butterfly Arithmetic قابل انتخاب است. به طور کلی دو انتخاب وجود دارد که گزینه اول مجدداً به CLB ها و گزینه دوم به XtremeDSP Slices اختصاص دارد.
خب مسیر سفارشی سازی نسبتاً طولانی بود. بعد از تعریف تمام پارامترها روی Generate کلیک کنید تا خروجی نهایی تولید شود و بعد از تولید IP Core میتوانید به سادگی آن را به طرح خودتان اضافه کنید.
جمع بندی
محاسبه و پیاده سازی تبدیل فوریه در FPGA روی دنبالههای فریم بندی شده به عنوان بخش جدایی ناپذیر سیستمهای پردازش سیگنال شناخته میشود. به کمک این مقاله شما یک دید کلی در رابطه با Xilinx FFT IP Core و تنظیمات بخشهای مختلف آن بدست آوردید، اما برای اینکه به تمامی جزئیات پیاده سازی FFT مسلط شوید، نیاز دارید دیتا شیت DS260 را به صورت کامل مطالعه بفرمایید. دقت کنید که شما برای استفاده از FFT IP Core باید آشنایی کافی با دیاگرام زمان بندی، پورتها و نحوه کنترل آن داشته باشید. برخلاف بسیاری از IP Core ها، شرکت Xilinx برای FFT IP Core تست بنچ و مثال آماده ارائه نکرده است، از این رو مسئولیت نوشتن تست بنچ بر عهده خودتان است.
پیاده سازی الگوریتم تبدیل فوریه در FPGA کار چندان آسانی نیست، اما در عمل نیازی هم به آن نیست چون Xilinx این کار را به شکل کاملاً بهینه برای شما انجام داده است.
منبع: Xilinx ، Allaboutcircuits






4 دیدگاه برای “تبدیل فوریه در FPGA با Xilinx FFT IP Core”
با سلام و احترام و خسته نباشید
بنده نیاز به طراحی یک fft64 را دارم که ورودی سینوسی به آن اعمال شود
1- برای انجام این پروژه استفاده صرف از ip corها کافی می باشد یا حتما بایستی از برنامه نویسی در این زمینه استفاده کرد.
2- آیا امکان دارد در این زمینه بنده را کمک کنید البته با تقبل هزینه. (البته کننده کار خودم باشم و شما عزیزان در انجام این کار بندخ را اراهنمائی بفرمائید)
ممنون می شم در این خصوص بنده را راهنمائی بفرمائید.
سلام، قادر عزیز از حسن توجه شما به این مقاله سپاسگزاریم.
اگر منظور شما از fft64 یک fft با ۶۴ نقطه است و ورودی شما یک ورودی حقیقی است. در این صورت شما می توانید با استفاده از ip core و بدون کد نویسی طراحی مد نظرتون و اجرا کنید. دقت کنید که fft روی سیگنال های مختلط اجرا می شود ، پس باید به جای بخش موهومی سیگنال ورودی صفر قرار دهید.
در صورت نیاز به راهنمایی بیشتر از طریق شبکه های اجتماعی با ما همرا باشید.
بسیار عالی
خدا قوت
درود فراوان بر شما
همراهی و لطف شما باغث افتخار ماست.