
مقدمه
این نوشتار از پایگاه دانش هگزالینکس یک بروزرسانی برای مقالهای است که پیش تر تحت عنوان بلوکهای DSP48 : قلب تپنده پردازش سیگنال منتشر شده است و در آن تاریخچه پیداش بلوکهای DSP48 و سیر تکاملی آن در طی یک بازه زمانی ۱۵ ساله به شکل خلاصه مورد بررسی قرار گرفت. در ادامه قصد داریم بلوکهای قدرتمند پردازش سیگنال در تراشههای Versal را که بلوکهای DSP58 نام دارند، به علاقمندان و طراحان سخت افزار معرفی کنیم.
تراشههای Versal
شرکت Xilinx در سال ۲۰۱۸ از جدیدترین نسلِ تراشههای قابل پیکره بندی خودش تحت عنوان Versal رونمایی کرد. با وجود اینکه تراشههای خانواده Versal، قابل پیکره بندی هستند ولی از نظر Xilinx نباید FPGA یا SoC نامیده شوند. تراشههای خانواده Versal با نام تجاری ACAP (اِیکپ) مخفف عبارت adaptive compute acceleration platform به عنوان یک بستر انعطاف پذیر و شتاب دهنده با تکنولوژی 7nm به بازار معرفی شدهاند. میزان تغییرات اعمال شده روی تراشههای ACAP نسبت تراشههای FPGA خانواده +UltraScale/UltraScale بسیار چشمگیر است، و عملاً در این تراشهها، FPGA یک بخش نسبتاً کوچک را به خودش اختصاص میدهد. در عمل تراشه Versal برای پاسخگویی به پردازشهای مورد نیاز در هوش مصنوعی تولید شده است.
ویژگیهای بلوکهای DSP58
تمامی تراشههای Versal از نسل جدید و بهبود یافته DSP48E2 Slice که در تراشههای +UltraScale/UltraScale معرفی شدند و در مقاله بلوکهای DSP48 : قلب تپنده پردازش سیگنال مورد بررسی قرار گرفتند، استفاده میکنند. نسل جدید این بلوکهای محاسباتی پردازش سیگنال به اختصار DSP58 نام گذاری شده است و بهینه سازیهای گستردهای در مقایسه با نسل قبلی روی آن اعمال شده است.
اول از همه ضرب کننده علامت دار مرکزی که در نسل قبلی قادر به محاسبه عملیات ضرب ۱۸×۲۷ بیتی بود حالا قادر به محاسبه حاصل ضرب دو سیگنال ۲۴×۲۷ بیتی است و طول بیت جمع کننده انباره آن نیز از ۴۸ بیت به ۵۸ بیت افزایش یافته است، و این تغییر دقیقاً همان ویژگی برجستهای است که در نهایت بعد از بیش از یک دهه باعث تغییر نام DSP Slice ها از DSP48 به DSP58 شده است. این دو ویژگی جدید در کنار یکدیگر باعث تسهیل چشمگیر فرایند پیاده سازی فیلترهای FIR بزرگ شدهاند. در حقیقت بعد از این قادر خواهیم بود حاصل جمعِ ۲۵۶ حاصل ضرب ۲۴×۲۷ بیتی را بدون نگرانی بابت وقوع سر ریز و بدون استفاده از منابع منطقی درون تراشه و تنها با استفاده از اتصال آبشاری بلوکهای DSP58 محاسبه کنیم. همچون نسلهای قبلی قابلیت شیفت روی خروجی P همچنان پشتیبانی میشود و میتواند برای پیاده سازی ضرب کننده بزرگتر مورد استفاده قرار بگیرد و از این نظر سازگاری کامل با DSP48 ها وجود دارد، البته قابلیت شیفت از ۱۷ به ۲۳ بیت افزایش یافته است. از این رو امکان ساخت ضرب کنندههای به مراتب بزرگتر نیز وجود دارد.
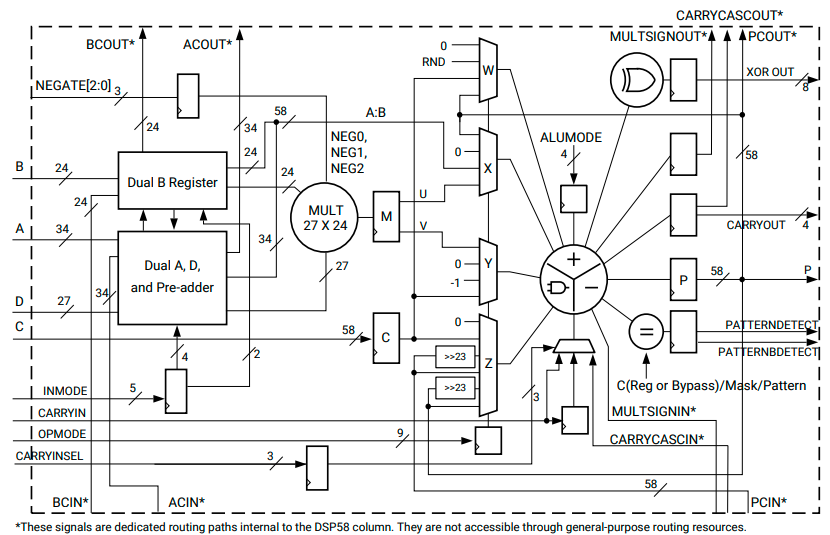
بلوکها DSP58 ششمین نسل بلوکهای DSP شرکت Xilinx هستند و از چند مد کاری استاندارد پشتیبانی میکنند که در ادامه توضیح داده میشوند. این مدها عبارتند از:
- مد کاری DSP58 INT8 Vector Dot Product
- مد کاری DSP58
- مد کاری DSPFP32
- مد کاری DSPCPLX
اولین ویژگی جدید و کاملاً منحصر به فرد این بلوکها پشتیبانی از مد INT8 یا Vector Dot Product است. در این مد پورت ۲۷ بیتی A میتواند به سه بخش ۹ بیتی با نامهای A2 و A1 و A0 و پورت ۲۴ بیتی B هم مشابهاً میتواند به سه بخش ۸ بیتی B2 و B1 و B0 تقسیم شود. با این تقسیم بلوک DSP58 قادر به محاسبه سه ضرب کوچکتر و در ادامه محاسبه حاصل جمع آنها خواهد بود. یعنی امکان محاسبه کامل عبارت P=±A2*B2±A1*B1±A0*B0 وجود دارد. این ویژگی جدید تأثیر قابل ملاحظهای روی کیفیت پیاده سازی الگوریتمهای هوش مصنوعی همچون شبکههای عصبی عمیق به ارمغان میآورد.
مدهای ۱۲ بیتی و ۲۴ بیتی SIMD و همینطور انجام محاسبه XOR عریض روی سیگنالهایی با عرض بیت ۱۲ و ۲۴ و ۴۸ و ۹۶ بیتی همچنان امکان پذیر است، علاوه بر این بلوکهای DSP58 محاسبات XOR عریض با طول بیتهای ۲۲ و ۳۴ و ۵۸ و حتی ۱۱۶ بیتی را نیز پشتیبانی میکنند.
دیگر ویژگی جدید بلوکهای DSP58 مربوط به مد DSPCPLX است. در این مد با اتصال آبشاری دو DSP58 مجاور امکان پیاده سازی یک ضرب کننده مختلط ۱۸×۱۸ بیتی مهیا میگردد، در این مد کاری اولین DSP58 بخش حقیقی و دومین DSP58 بخش موهومی را محاسبه میکند. جالب اینجاست که جمع کننده انباره خروجی نیز به صورت مختلط عمل میکند. این ویژگی از نقطه نظر منابع مصرفی بسیار ارزشمند است، زیرا در گذشته سه یا چهار بلوک DSP48 برای پیاده سازی ضرب مختلط مورد نیاز بود.
در نهایت بلوکهای DSP58 جدید در مد DSPFP32 از محاسبات ممیز شناور نیز پشتیبانی میکنند. یک بلوک DSP58 میتواند یک ضرب ممیز شناور FP32 و یا FP16 همراه با یک جمع کننده انباره FP32 پیاده سازی کند. پیش تر در تراشههای UltraScale برای این کار بین ۲ تا ۴ بلوک DSP48E2 به همراه چند صد LUT و FF مورد نیاز بود.
مشابه تمام بلوکهای DSP48 روشهای متفاوتی برای فراخوانی بلوکهای DSP58 وجود دارد که در جدول زیر قابل مشاهده است. اما برای استفاده از Primitive ها و یا Macro های آماده باید به دنبال نامهای DSP58 و DSP58CPLX و DSPFP32 در پنجره Language Template بگردید.

برای آشنایی با نحوه استفاده الگوهای آماده Xilinx و پنجره Language Template کافی است مستندات محیط توسعه Vivado یا مقالات منتشر شده در وبلاگ هگزالینکس را مطالعه بفرمایید.
جمع بندی
پلتفرم Versal به شکل کلی قواعد بازی و فضای ذهنی ما از تراشههای قابل پیکره بندی را تغییر داده است. بلوکهای DSP58 تنها یکی از صدها ویژگی منحصر به فردی است که این تراشهها با خود به ارمغان آوردهاند. در دنیایی که ما درآن زندگی میکنیم، نزاع بین سخت افزار و نرم افزار روز به روز شکل جدی تری به خودش میگیرد و چالشهای پیاده سازی به شکل مداوم با ظهور پلتفرمها پردازشی قدرتمندتر یکی پس از دیگری پشت سرگذاشته میشوند. شاید چالشهای پردازش سیگنالی که انتظار میرود توسط بلوکهای DSP58 مرتفع گردند، در آینده نزدیک جای خود را به نیازمندیهای جدیدی بدهند که این موتورهای قدرتمند پردازشی هم در برآورده کردن آن ناتوان باشند.





